AI Agent For Processing Electronic Medical Records
June 2024
Optimization of an N8N-based data processing pipeline: product-matching improvement using LLMs, prompt engineering, and migration from SQL lookups to vector search.
Our client is a consumer electronics reseller managing a constantly updating catalog of products purchased from multiple suppliers. Their internal database stores all active items in stock, and every new supplier price list, often thousands of SKUs, must be matched against this database.
The challenge: supplier naming conventions varied significantly, even for identical products. As a result, automated matching frequently failed, forcing the client’s team to manually inspect mismatches, resolve naming conflicts, and add missing items to appropriate categories.
They already had a processing pipeline built in N8N, but it struggled with:
The client approached us to optimize the entire pipeline, improve accuracy, and dramatically reduce execution time.
We redesigned the pipeline with a focus on performance, reliability, and scalable LLM usage.
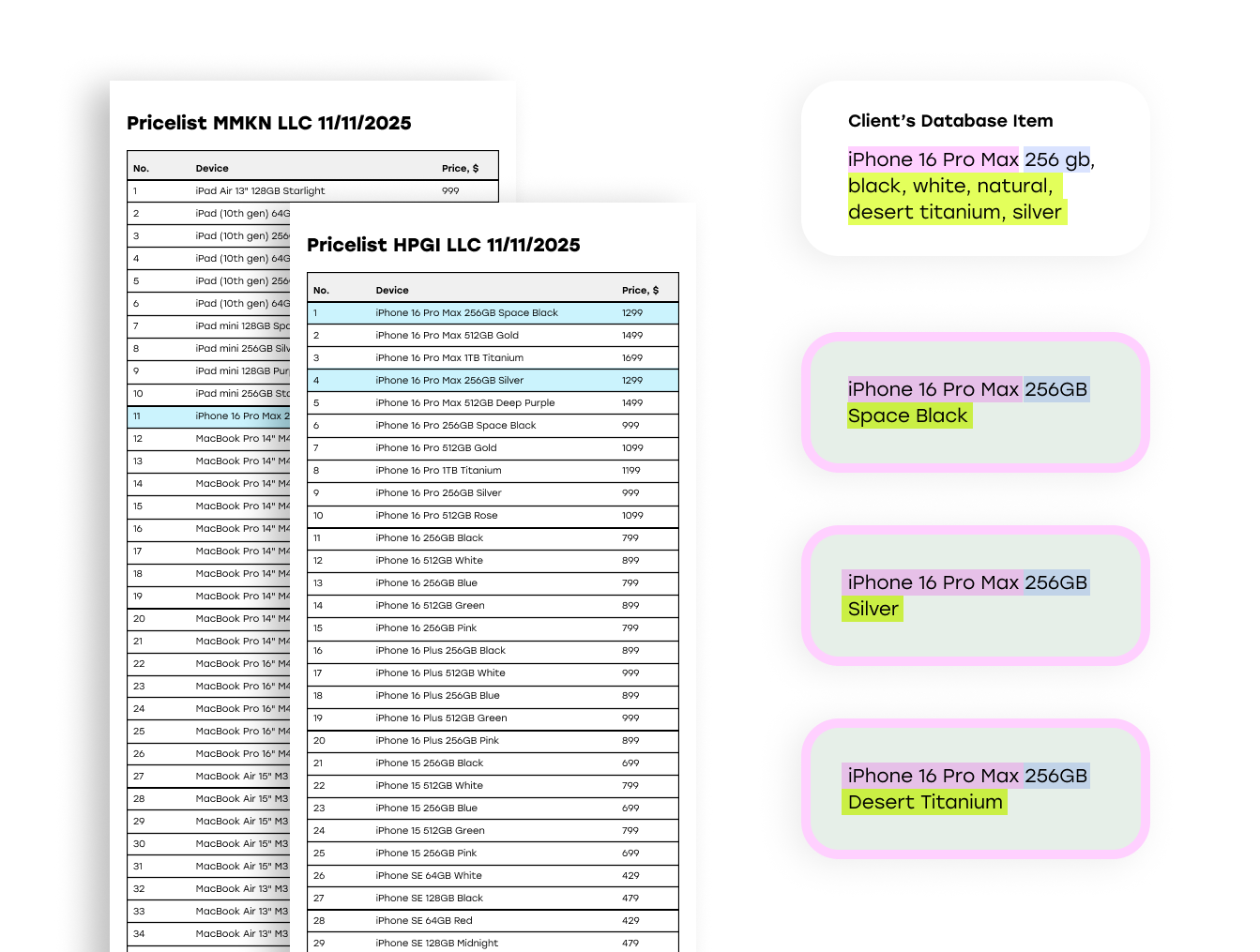
We reworked the LLM prompts responsible for product classification and similarity matching. The client’s original prompts were written in a free-form style and executed as separate steps, forcing multiple LLM calls for a single item.
We redesigned them into structured instructions and merged previously independent tasks into one cohesive prompt. This significantly improved response stability and reduced the number of model interactions required during processing, leading to a 2.5x faster LLM processing.
The existing N8N workflow contained unnecessary branching and operation sequences that slowed down processing of large supplier price lists.
We refactored the pipeline to minimize processing steps and focus on performance. As a result, the workflow is now capable of handling daily imports of thousands of records without the delays the client previously experienced.
A major bottleneck was the database: each product triggered an individual SQL query. With large catalogs, this approach scaled poorly.
We implemented the Qdrant vector database to enable semantic matching and bulk similarity search, allowing fast retrieval of relevant candidates and more accurate product matching despite varying supplier naming conventions.
Benefits:
The upgraded system delivered a substantial performance improvement:
The optimized workflow now processes large supplier price lists quickly and reliably, enabling the client to maintain an up-to-date product catalog with minimal manual intervention.
Do you want to know the total cost of development and realization of the project? Tell us about your requirements, our specialists will contact you as soon as possible.