Introduction
This benchmark explores how well AI models handle the processing of complex tables from construction drawings. Read on to learn:
- Which AI model reached 100% accuracy on simple architectural schedules — and outperformed competitors by 20–60% in overall table extraction,
- Why Google’s layout parser failed to detect door and window schedules entirely — and which tools proved reliable in real-world conditions,
- How well modern AI services handle complex layouts, multi-line cells, and measurement data — and which ones hallucinate or fabricate table content.
We regularly benchmark AI models to find the best ones for digital document processing for different applications. Take a look at our previous report where we’ve tested 7 AI models on invoices of various years and a comprehensive report on all of our tests.
IDP Models Benchmark
We are constantly testing large language models for business automation tasks. Check out the latest results.
Processing Complex Tables In Construction Drawings
In architectural and construction documentation, schedules refer to organized sets of supplementary data, usually displayed in table format. These tables contain detailed information that would otherwise overwhelm and clutter the main drawings if included directly on the plans.
A door and window schedule is a tabular representation of doors and windows in a building, detailing their specifications and features. It's a crucial part of architectural and construction drawings, providing a structured way to document various attributes of each opening.
For example, window and door schedules offer essential details a contractor needs for installation. They specify the types and locations of windows and doors throughout the building, along with associated hardware and finishes.
Often, there are also separate schedules for hardware, finishes, fixtures, and equipment, all designed to keep the construction documents clear and manageable.
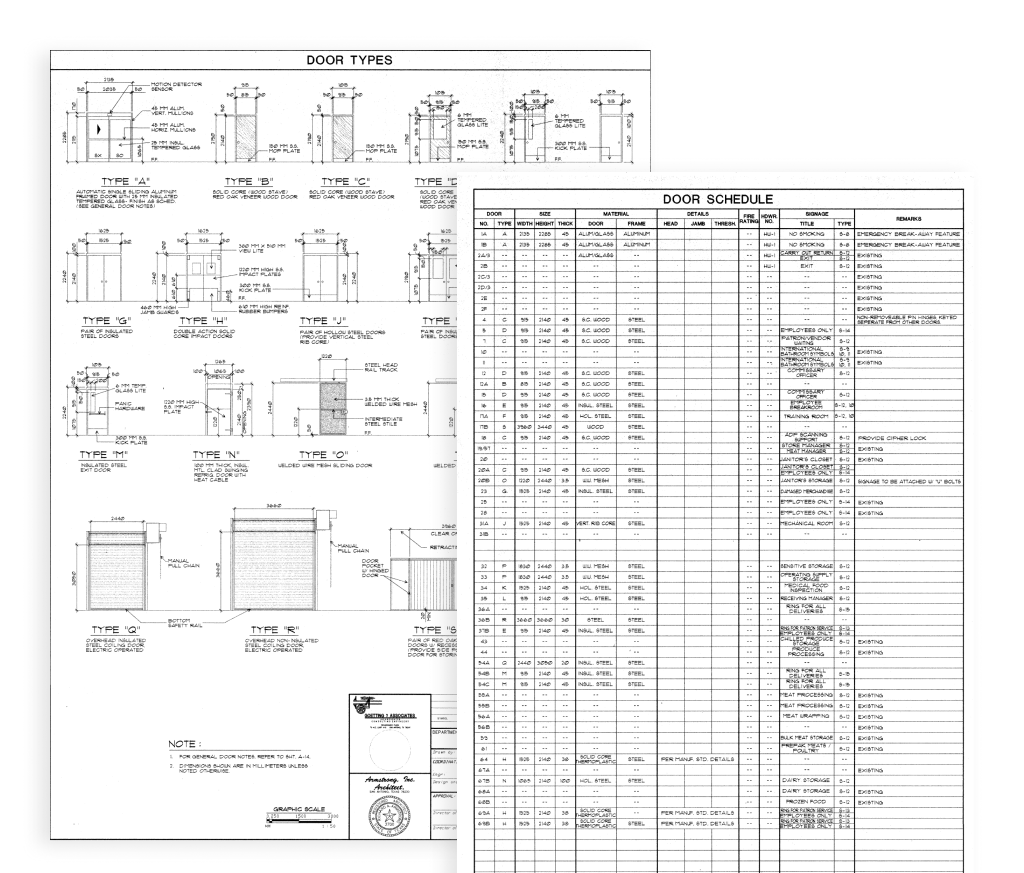
.png)
Experience AI for Engineering Drawings
Tested AI Models
In this benchmark, we have tested 7 popular AI services capable of processing tabular data:
- Amazon boto3 textract, or ‘AWS’
- Azure Prebuilt Layout, or ‘Azure’
- GPT-4o API, or ‘GPT’
- Gemini 2.5 pro preview 05-06, or ‘Gemini’
- Grok 2 vision 1212, or ‘Grok’
- Pixtral large latest, or ‘Mistral’
- Google Layout Parser, or ‘Google’
Dataset & Testing Method
Dataset: 18 architectural drawings in English, each containing one or two tables of door/window schedules, 20 schedules overall. Table dimensions ranged from small (7 rows × 3 columns) to large (38 rows × 18 columns).
Metrics: We used 2 metrics to evaluate models’ performances:
- Total Cells = rows × columns (including heading cells).
- Efficiency (%) = (correctly detected cells)/(total cells) × 100%.
Procedure: All models processed the same PDF inputs. We compared ground-truth cell contents to each model’s JSON-extracted table fields.
Construction Drawing Schedule Extraction Results
Note: Google, Grok and Mistral were excluded from the comparison after realising they are not suited for this specific task based on the results. Refer to the ‘Key Findings’ section of the article to learn why.

According to the benchmark results, Gemini showed the highest extraction efficiency, while GPT is significantly behind.
Key Findings from AI Table Recognition Tests
Simple Table Layouts Enable 100% Accuracy Across AI Models
Three models — Azure, AWS, Gemini — achieved 100% accuracy when processing Sample 6.

Factors contributing to perfect performance:
- Simple layout: single-line text and single level headings.
- Uniform, legible font.
- No complex data (e.g. size data using the feet and inches format).
Insight: Simple structure and clarity in data lead to better detection across platforms.
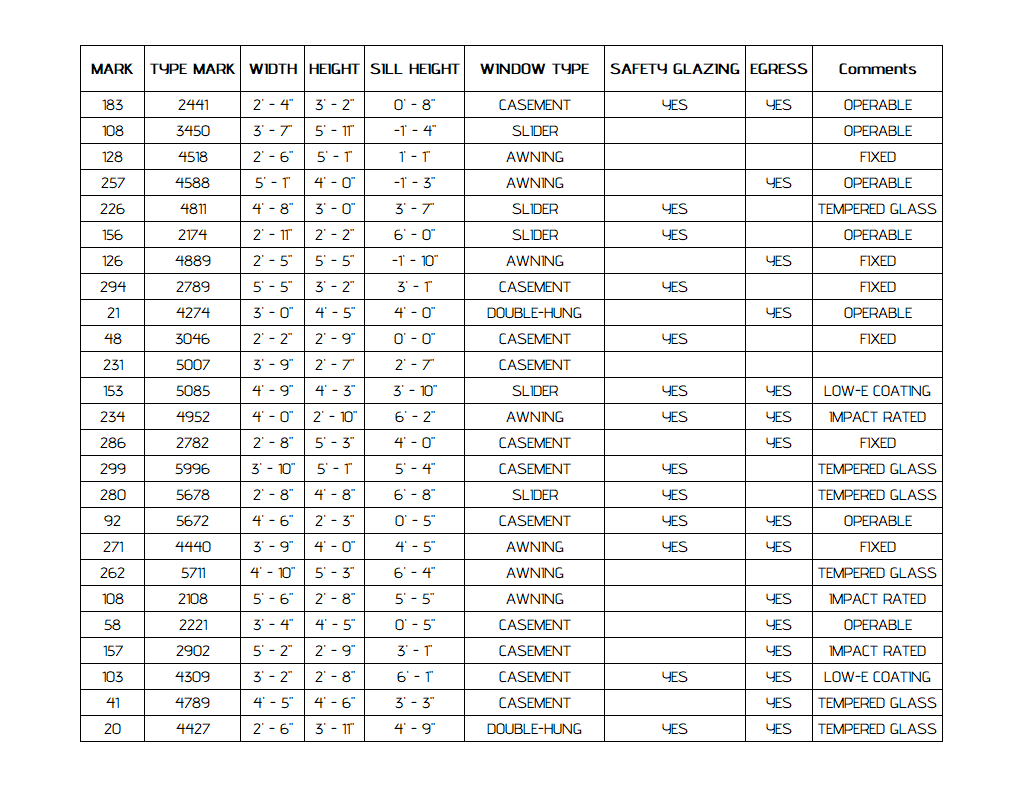
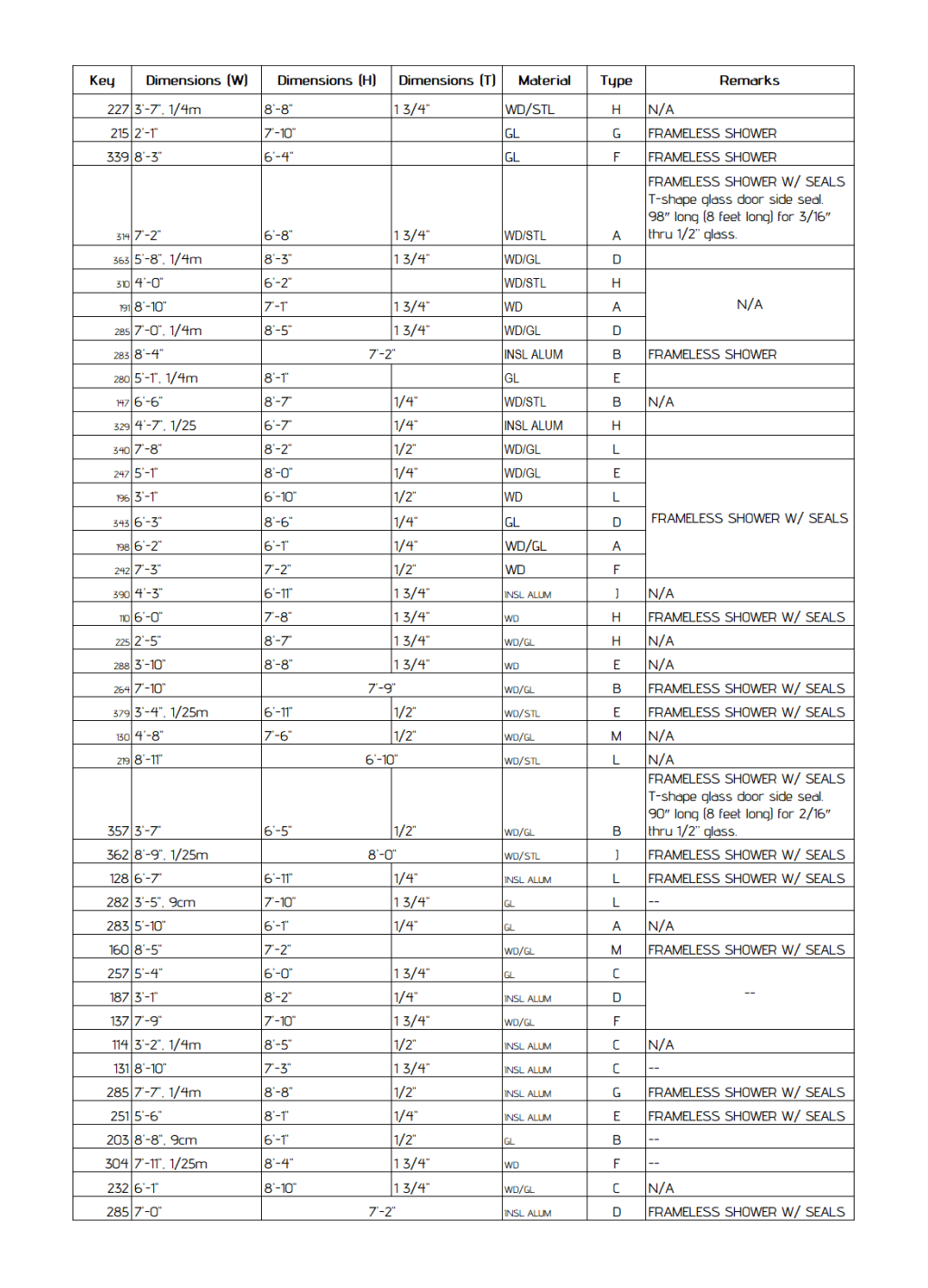
Table Complexity Significantly Decreases Performance
Sample 1, a table featuring a more complex layout, proved to be the most challenging for all AI services tested. Performance dropped to 55.00% for Azure, 66.67% for AWS, and 79.17% for Gemini—the latter typically being the top-performing model in this benchmark.

Key reasons for worse model performance:
- Unusual font and multi-line text
- Complexity in data, like long strings of text, size measurements in multiple units, size and text data mixed up in one cell
Insight: Visual and semantic complexity can degrade model performance.
GPT-4o Falls Short: Incomplete Outputs and API Limitations
GPT-4o demonstrated significant shortcomings in structured table extraction from architectural documents. Across multiple samples, the model consistently failed to return complete outputs, making it the lowest-performing tool in this evaluation at 38.41% extraction accuracy.
Core Issues Identified:
- Truncated Output: Tables were frequently cut off mid-way, with missing rows or columns.
- Incomplete Cell Data: Even when table structure was preserved, many cell values were only partially extracted or completely omitted.
These issues point to systemic limitations in how GPT-4o’s current API handles large structured outputs.
It’s important to note that prompt engineering and increasing document resolution didn’t improve the extraction accuracy.
Insight: Gpt is not suitable for full-table extraction tasks in its current API configuration. Performance bottlenecks are likely model-side, not user-side.
Grok Model Issues: Hallucinations and Pattern Fabrication
Grok 2 Vision 1212 has a critical flaw: its reliance on heuristic pattern fabrication. Rather than faithfully transcribing tabular data, Grok often generated entries that never existed in the source document:
- Follows non-existent patterns (e.g., sees "1, 2" and auto fills up to "10").
- Replaces unique values with frequent ones in a column, suggesting a mode bias.
Below in a side-by-side comparison showing deviation from source data:
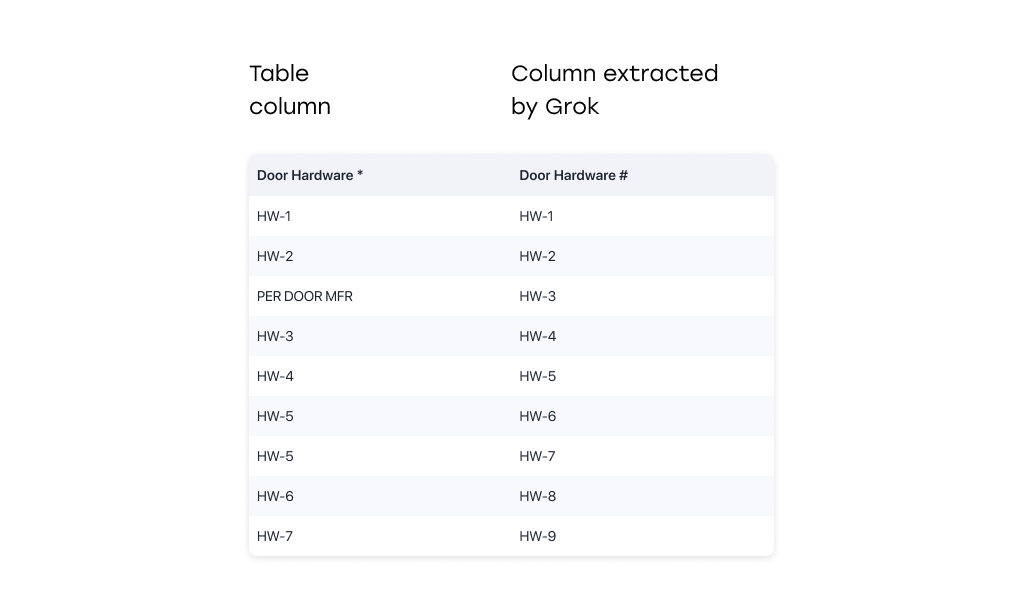
Insight: Grok’s heuristics are unreliable for structured table extraction tasks. It was excluded from the comparison.
Mistral: Hallucinations, Pattern Fabrication, and Data Mix-ups
The Pixtral Large (Mistral) model exhibited one of the most severe forms of failure — not only misinterpreting table content, but inventing data outright.
Key problems:
- Follows non-existent patterns, replaces unique values with frequent ones
- Additionally, returned content that did not exist in the document at all — suggesting deeper generation inaccuracies.
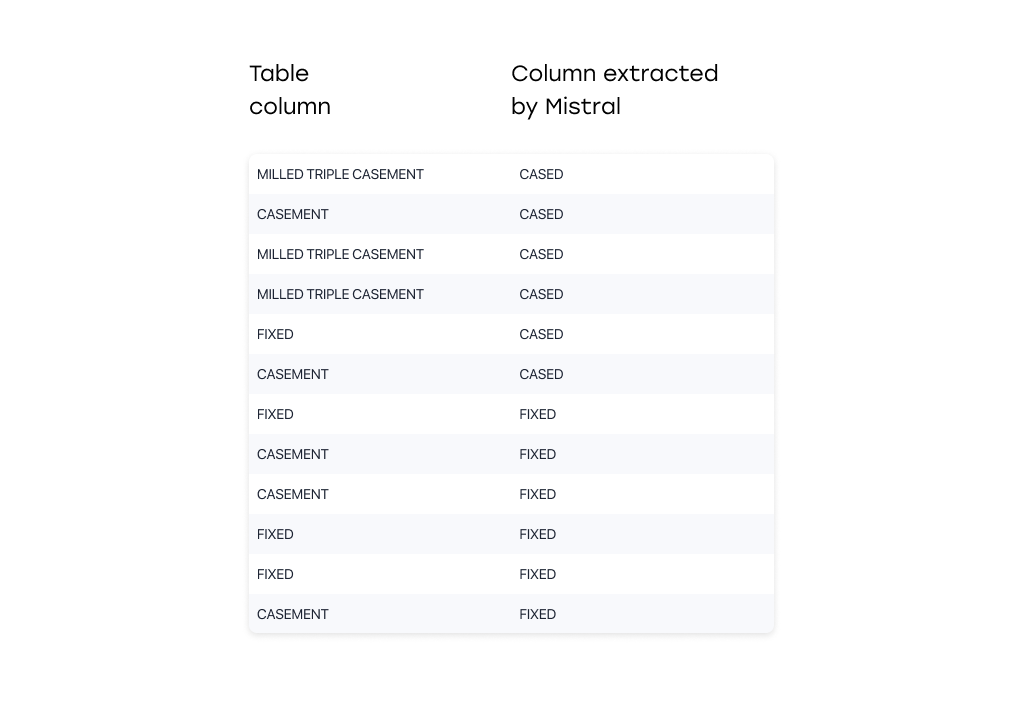
Insight: Mistral exhibited reliability problems, fabricating content during extraction. It was excluded from the comparison.
Google Vision: Inability to Detect Relevant Tables
The Google Layout Parser was unable to recognize the core structures required for this task: structured data like door and window schedules.
Core issues:
- Failure to Detect Tables: The model did not identify door or window schedules as tabular data.
- Irrelevant Outputs: Instead of returning structured content, it extracted unrelated blocks of text scattered throughout the page.
Insight: Google lacked functional table detection for the tested documents, and was excluded from the comparison.
Benchmark: Best AI Models For Engineering Drawing Processing
Does Table Size Affect AI Efficiency?
A common assumption in document AI is that the complexity of a table—often measured by its number of rows, columns, or total cells—can negatively impact the accuracy and efficiency of data extraction.
We tested this hypothesis and plotted Azure, AWS and Gemini efficiency against:
- Number of rows
- Number of columns
- Total number of cells (rows × columns)
Analysis
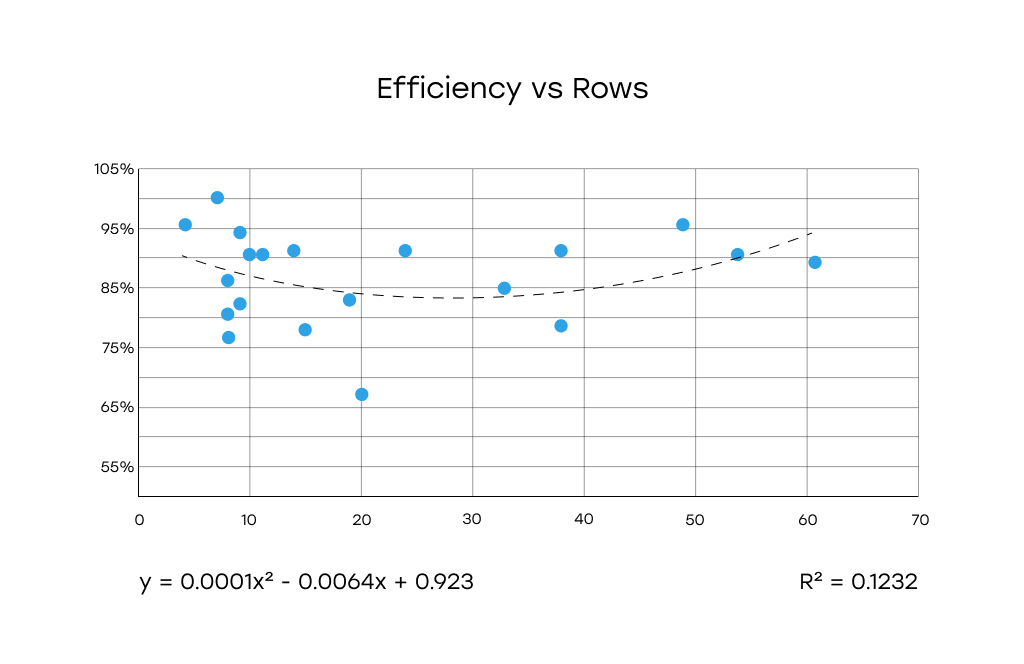
Efficiency vs Rows: the graph indicates a weak correlation. There may be a minor non-linear pattern, but the relationship is not strong or conclusive.
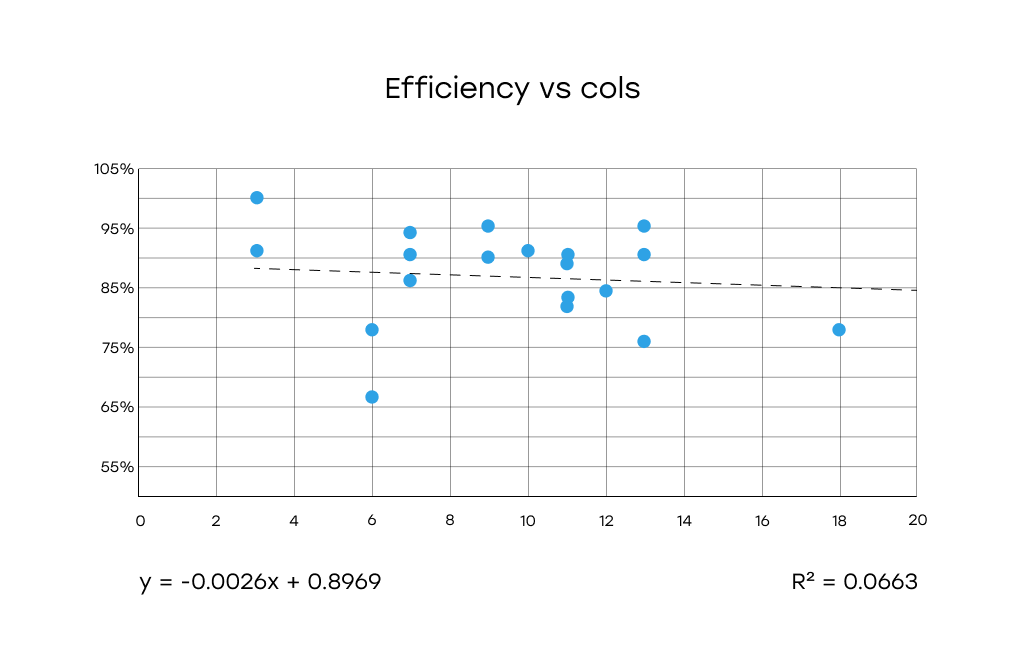
Efficiency vs Columns: The data points are highly scattered. The number of columns does not appear to significantly impact detection efficiency.
Efficiency vs Total Cells: No meaningful correlation between total number of cells and detection efficiency.
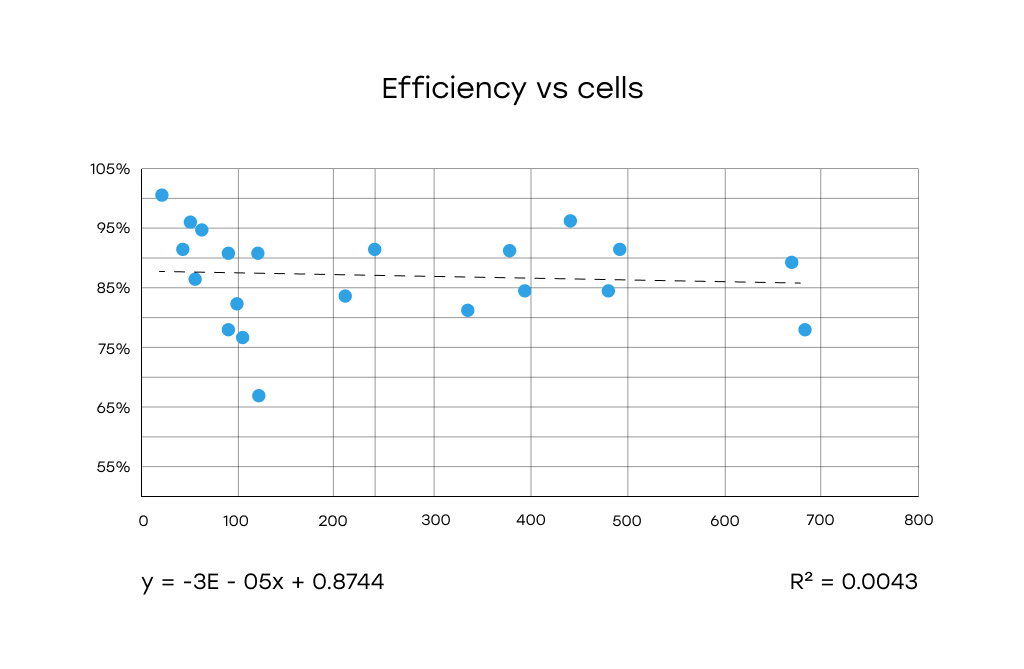
Comparative Analysis (Azure, AWS, Gemini):
- Gemini consistently outperformed both Azure and AWS, showing high and stable efficiency even at larger cell counts.
- Azure and AWS showed more variability and drops in performance, especially in the 100–300 cell range.
- However, even across all services, no clear downward trend was observed with increasing cell count.
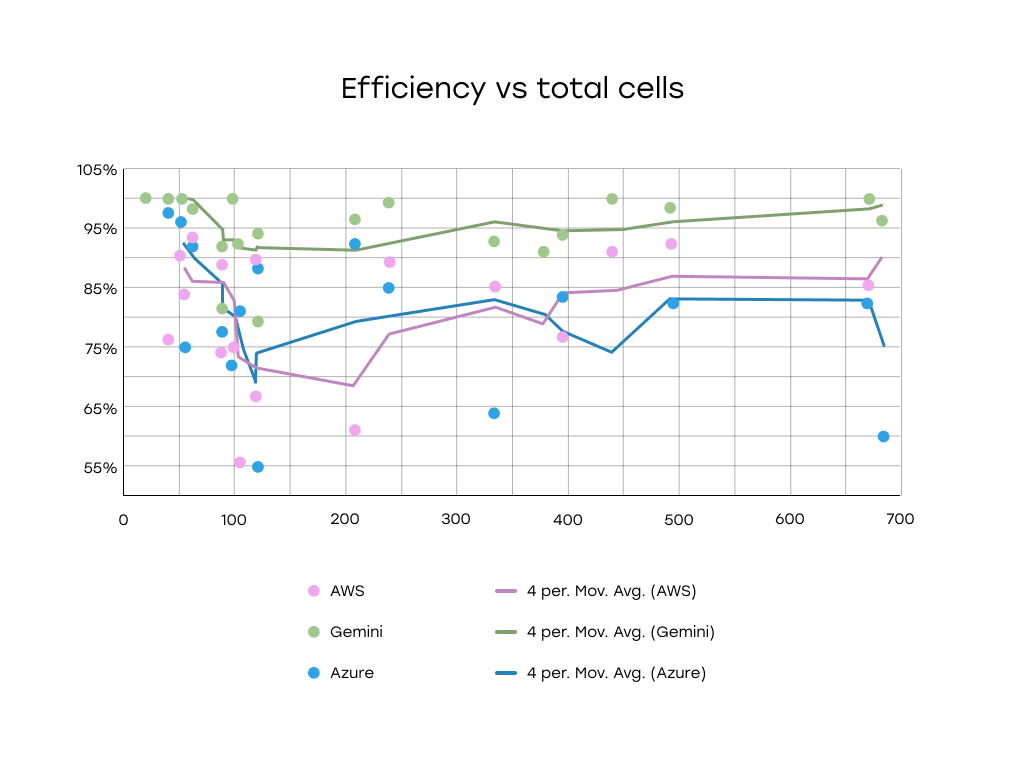
Conclusion: Table Size Alone Doesn’t Predict Extraction Efficiency
The analysis revealed no strong or consistent correlation between table size (in terms of rows, columns, or total cells) and detection efficiency.
While certain services, notably Gemini, maintain high performance across a wide range of table sizes, the overall variability in performance appears to be influenced by other factors not captured in cell count alone.
Final Evaluation: How AI Models Handle Architectural Schedule Extraction

Model Performance & Accuracy
- Gemini 2.5 Pro delivered the highest overall extraction accuracy, consistently outperforming other models even on larger and more complex schedules.
- Azure and AWS Textract showed solid baseline performance but struggled with tables that included multi-line cells, unusual fonts, or mixed content formats.
- GPT-4o suffered from incomplete outputs, likely due to API output or context constraints, leading to the lowest average accuracy across all tested models.
- Grok and Mistral were excluded from detailed comparison due to hallucinated data and fabricated patterns, making them unreliable for structured extraction.
- Google Layout Parser failed to detect architectural schedules as tables, returning unstructured text instead—rendering it inapplicable for this use case.
Efficiency & Cost Considerations
- Gemini achieved the most accurate extractions but incurred significantly higher processing times and costs (~47 seconds per page at $58/1,000 pages).
- AWS and Azure were more cost-effective and faster (2.9s and 4.3s per page, respectively), offering viable options for applications where moderate accuracy is acceptable.
- GPT-4o had moderate speed and cost, but its output truncation limits its usefulness for full-table extraction workflows.
Final Recommendations
- For high-fidelity architectural table extraction, Gemini is the most capable and consistent, especially for complex layouts and larger schedules.
- For cost-sensitive or real-time applications, AWS and Azure offer reliable alternatives for simpler tables and structured layouts.
- GPT-4o should be avoided for full-table extractions unless API output limits are addressed.
- Grok, Mistral, and Google Vision are not recommended due to severe reliability issues, including data hallucination and failure to detect structured tables.
- Regardless of the tool, ensure document layout quality and clarity, as these have a more significant impact on model performance than table size alone.