Document extraction with AI encompasses a wide range of capabilities that revolutionize how businesses handle their data. At its core, AI-powered document extraction leverages advanced machine learning algorithms and natural language processing techniques to sift through vast volumes of documents, discerning patterns, entities, and relationships with remarkable accuracy.
These capabilities enable organizations to automate the extraction of valuable insights from both unstructured and structured documents, significantly enhancing operational efficiency and decision-making processes.
Describe your idea and get an estimation for your AI project
Contact UsUnstructured Data Extraction
Unstructured data extraction represents a critical frontier in the realm of information management, offering organizations the opportunity to unlock valuable insights from a diverse array of document types.
This process involves harnessing the power of artificial intelligence (AI) technologies to sift through vast volumes of unstructured data, such as emails, news articles, legal documents, and scientific papers, to extract meaningful information.
Unlike structured data, which adheres to predefined formats or schemas, unstructured data lacks a consistent organization, making it inherently challenging to extract insights manually.
Newspaper articles present an example of unstructured data that can yield valuable insights when properly extracted. Newspaper articles often contain a mix of textual content, images, and metadata, making it challenging to extract relevant information manually.
By leveraging AI-driven extraction techniques, you can automatically parse newspapers, extracting essential details such as headlines, publication dates, author names, and article content for digital archiving and research purposes.

Legal documents represent another example of unstructured data that can benefit from AI-powered extraction technologies. Legal documents, such as contracts, agreements, and court filings, often contain dense, complex language and intricate formatting.
Extracting key provisions, clauses, and dates from legal documents manually can be labor-intensive and prone to errors. However, with AI-driven extraction tools, organizations can automate this process, accurately identifying and extracting critical information from legal documents, thereby streamlining contract management and compliance efforts.

Structured Data Extraction
Structured data extraction is a pivotal component of document processing, enabling the extraction of valuable information from documents that adhere to predefined formats or schemas.
Unlike unstructured data, which lacks a consistent organization, structured data follows a predefined structure, making it easier to extract and analyze. Examples of structured documents include forms, invoices, receipts, surveys, and contracts, each containing valuable data elements that can be extracted using AI-powered technologies.
Forms represent one of the most common types of structured documents, often used for data collection purposes in various industries. From employment applications to customer surveys, forms contain fields for capturing specific pieces of information, such as names, addresses, dates, and responses to specific questions.
AI-driven extraction tools can automate the process of parsing forms, accurately identifying and extracting data from each field with precision. This capability streamlines data entry processes, reduces errors, and improves data accuracy, ultimately enhancing organizational efficiency.
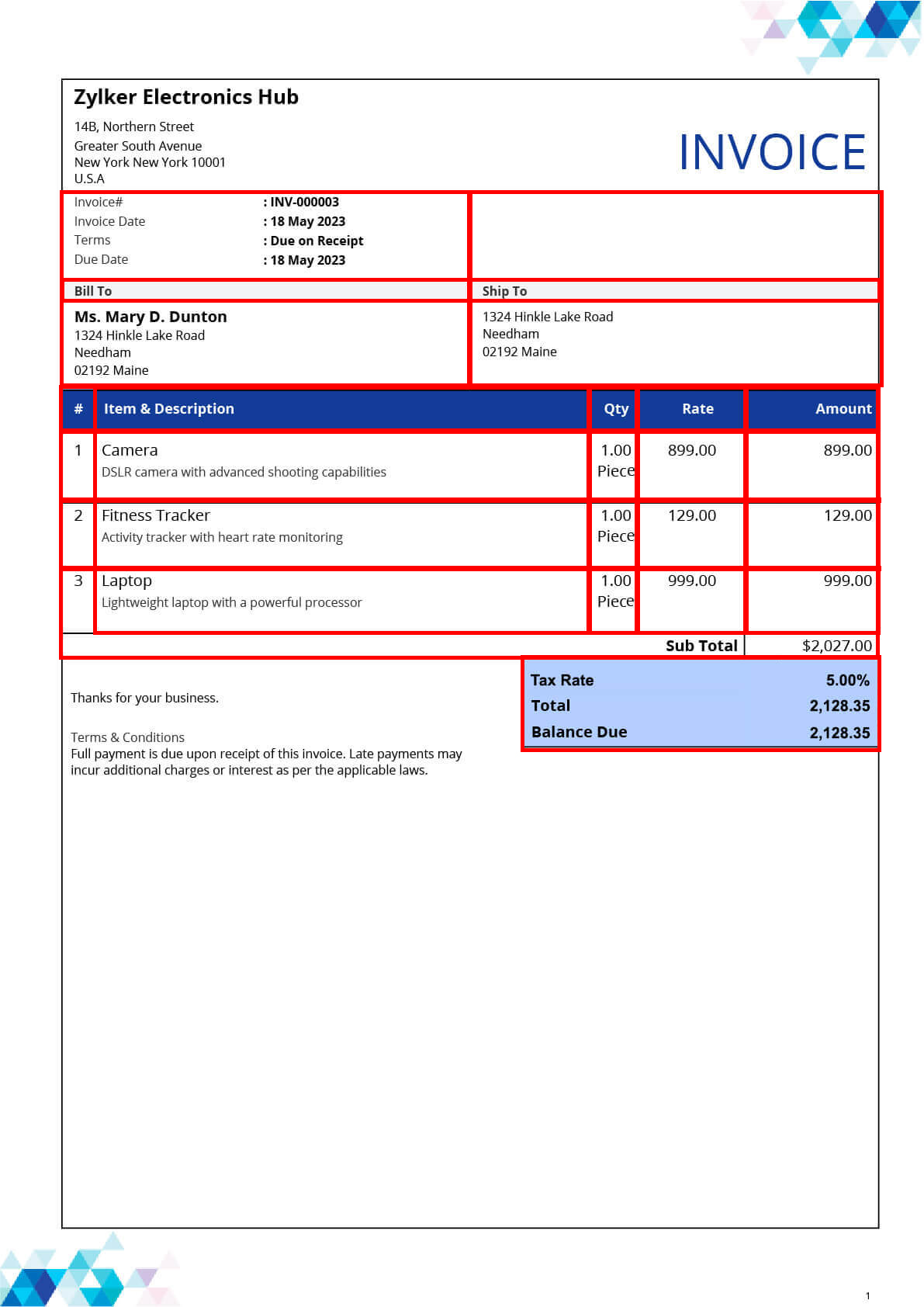
Invoices and receipts are another example of structured documents that lend themselves well to AI-powered extraction techniques. These documents typically contain essential information such as billing details, line items, payment terms, and tax amounts, all of which need to be accurately extracted for accounting and financial analysis purposes.
With AI-driven extraction tools like GD Picture and OpenCV, organizations can automate the extraction of key invoice and receipt data, facilitating faster invoice processing, expense tracking, and financial reporting.
Processing of complex structures, tables, hand written text, images and graphs
The processing of complex structures, tables, handwritten text, images, and graphs represents a significant challenge in document extraction, as these elements often require specialized techniques to accurately interpret and extract information.
However, advancements in artificial intelligence (AI) technologies have enabled organizations to tackle these challenges effectively, unlocking valuable insights from diverse document types.
Tables are commonly found in documents such as financial reports, scientific papers, and spreadsheets, and they often contain critical data points organized in rows and columns. AI-driven extraction tools can automatically identify and extract data from tables, even when they vary in size, format, or structure.
By leveraging techniques such as optical character recognition (OCR) and table recognition algorithms, organizations can extract structured data from tables with high accuracy, facilitating data analysis and decision-making processes.
.png)
Images and graphs are often used to convey complex information in documents such as presentations, reports, and research papers. While traditional extraction methods may struggle to interpret non-textual content, AI-driven image recognition algorithms can analyze images and graphs, extracting relevant data points and insights.
For example, AI-powered extraction tools can identify trends, patterns, and anomalies in graphs, enabling organizations to derive actionable insights from visual data.
Tools For PDF Data Extraction
Tools for PDF data extraction are essential for organizations looking to unlock valuable insights from their PDF documents. These tools leverage a combination of advanced technologies, including optical character recognition (OCR), natural language processing (NLP), and machine learning algorithms, to extract structured and unstructured data from PDF files accurately and efficiently.
iText
iText is a powerful library for PDF manipulation and extraction, allowing users to parse, modify, and extract data from PDF documents programmatically. With iText, organizations can automate the extraction of text, images, and metadata from PDF files, facilitating data analysis and decision-making processes.
One of the downsides of iText is its cost: compared to other tools for intelligent document processing, the distribution license of iText is the most expensive on this list. Depending on the project budget, the licensing cost might have a considerable impact on the overall cost of development.
GD Picture
GD Picture is another versatile tool for PDF data extraction, offering a wide range of features for document processing and image recognition. With GD Picture, users can extract text, images, tables, and other elements from PDF documents with ease, enabling efficient data extraction and analysis workflows.
We have found GD Picture to be the most balanced technology when it comes to detection accuracy and licensing cost. It’s worth mentioning the basic GD Picture version can only work with PDFs with a text layer, so for documents without a text layer you either need to upgrade to a different version of GD Picture or introduce other tools for extracting the text layer.
PDF Plumber
PDF Plumber is a Python library specifically designed for PDF extraction tasks, offering robust capabilities for parsing and extracting text and table data from PDF files.
In our experience, PDF Plumber, while being completely free, is the least accurate of all the tools on this list. We would not suggest the use of PDF Plumber for projects where high accuracy is paramount.
OpenCV
OpenCV, a popular computer vision library, can also be used for PDF data extraction tasks, particularly for extracting images, graphs, and primitives (basic structural elements of a document, like vertical and horizontal lines, boxes, etc.) embedded within PDF documents. With OpenCV's image processing algorithms, you can extract visual data from PDF files and analyze it to derive actionable insights.
OpenCV is a very powerful tool in the hands of an experienced AI software developer. OpenCV can handle complex tasks of data retrieval and extraction, detection of primitives, extraction and detection of both typed and handwritten text.
Azure Form Recognizer
Azure Form Recognizer is a cloud-based tool offered by Microsoft Azure for extracting structured data from PDF forms and documents. Using machine learning models, Azure Form Recognizer can automatically identify and extract key data fields from PDF files.
Azure Form Recognizer works best with US taxes forms, but can work on other document types. However, if you are looking to extract data from unstructured documents or documents other than taxes forms, we suggest using other tools to achieve higher recognition accuracy.
MLPClassifier
MLPClassifier is a machine learning algorithm commonly used for text classification tasks, including PDF data extraction. By training MLPClassifier models on labeled PDF data, organizations can develop custom solutions for extracting specific types of information from PDF documents, such as sentiment analysis, entity recognition, or document categorization.
Amazon Textract
Amazon Textract is a fully managed OCR service provided by Amazon Web Services (AWS), designed to extract text, tables, and forms from scanned documents, including PDF files. Amazon Textract is a great choice for processing structured documents, especially PDF files without a text layer.
This tool is great for performing the first step of intelligent document processing of PDF documents without a text layer — text extraction.
GPT-4 & ChatGPT
Finally, GPT-4, the successor to GPT-3, and ChatGPT, a variant of GPT specifically tailored for conversational AI, can also be utilized for PDF data extraction tasks. The popular OpenAI model is great for semantic search and intelligent document processing which includes post-processing of the extracted data.
Intelligent document processing using GD Picture and OpenCV
As a computer vision development company with strong expertise in intelligent document processing, we have developed multiple systems for processing both structured and unstructured documents. We have worked with various computer vision models, text extraction and processing tools, and language models to create powerful IDP digital systems.
While every AI document processing project requires research for the best approach to development, including testing various AI models and document processing tools, there are approaches that work universally good for certain types of document.
For the sake of the example, we will be describing the process of developing an AI system for PDF document processing using GD Picture and OpenCV.
Classify Document Type
Classifying document types using GD Picture and OpenCV is a crucial step in intelligent document processing workflow. This process involves leveraging advanced image recognition and machine learning techniques to identify and classify various document types based on their visual characteristics and content structure.
Firstly, the documents are preprocessed to enhance image quality and remove noise, ensuring optimal conditions for document analysis.
Next, feature extraction techniques are employed to extract relevant visual features from the document images. GD Picture and OpenCV provide a range of tools and algorithms for feature extraction, allowing customization of their approach based on the unique characteristics of their document datasets.
Once the visual features are extracted, machine learning models are trained to classify documents into predefined categories or classes. Supervised learning algorithms such as support vector machines (SVM), random forests, or convolutional neural networks (CNNs) can be trained using labeled datasets containing examples of various document types.
After training the classification model, it can be applied to new document images to automatically classify them into the appropriate document types. GD Picture and OpenCV provide APIs and libraries that facilitate the integration of trained models into document processing workflows.
Detect Basic Structural Elements
Detecting structural elements, also known as primitives, within documents using OpenCV is a fundamental task in intelligent document processing workflows. Structural elements encompass components such as paragraphs, headings, tables, and images, which provide the underlying structure of a document.
Here are the steps required to detect the primitives in a PDF document:
- The document images are preprocessed to enhance image quality and remove noise, ensuring optimal conditions for element detection.
- Contour detection techniques are employed to identify and extract regions of interest within the document images. Contours represent the boundaries of objects or structural elements within the image, such as text blocks, lines, and shapes. OpenCV provides various contour detection algorithms, such as the Canny edge detector and the findContours function, which can be used to identify and extract contours from document images.
- Next, additional filtering and processing techniques can be applied to refine the extracted structural elements further. For example, contour approximation algorithms can be used to simplify complex contours, while contour hierarchy analysis can be employed to identify hierarchical relationships between structural elements, such as nested text blocks within paragraphs or tables within documents.
- Lastly, structural elements are classified and labeled based on their visual characteristics and content structure. This may involve using machine learning techniques to train models that can classify structural elements into predefined categories, such as paragraphs, headings, tables, and images.
Extract Text from PDF
Extracting text from PDF documents is a fundamental task in document processing workflows.
Two common approaches to extracting text from PDF documents involve utilizing GD Picture with text layers and AWS Textract for documents without text layers. Each approach offers distinct advantages depending on the characteristics of the PDF files being processed.
PDF Document With Text Layer
With GD Picture, extracting text from PDF documents that contain a text layer is a straightforward process. PDF files with a text layer preserve the original textual content and formatting, making it easier to extract text accurately.
GD Picture provides robust tools and APIs for parsing PDF files, allowing to extract text with high fidelity while preserving formatting such as fonts, styles, and layouts. This approach is ideal for documents where maintaining text formatting and layout integrity is essential, such as contracts, reports, and legal documents.
PDF Documents Without A Text Layer
In contrast, extracting text from PDF documents without a text layer poses additional challenges, as these files contain images of text rather than searchable text content.
AWS Textract addresses this challenge by leveraging optical character recognition (OCR) technology to analyze the images and extract text accurately. Textract can detect and extract text from images, scanned documents, and PDF files without text layers. This approach is particularly useful for processing scanned documents, handwritten text, and images embedded within PDF files.
Looking for AI developers?
We create AI software — and we do it well. Talk to us to get your project started today
Form Key-value Pairs
Forming key-value pairs with a custom parser involves a systematic approach to extracting structured data elements from documents, particularly forms, surveys, and other structured documents. This process is essential for automating data extraction tasks and streamlining document processing workflows.

- Since the primitives have already been extracted at this point, the document layout is clear and identifiable. Text extraction using either GD Picture or AWS Textract also provides the content of the document.
- To proceed with the key-value pairing, you need to create a custom tailored to the specific layout and structure of the document using Python, Java, or C#, along with document processing libraries or frameworks such as Apache PDFBox, Tesseract OCR, or OpenCV. The custom parser is designed to parse the document images, identify key data fields and their corresponding values, and extract them into structured data formats such as JSON, XML, or CSV.
- Once the parser is deployed, it extract key-value pairings, like the field name and field input, i.e. “Name — Bobby Smith”.
Extract data Into Cloud, CRM, An Existing Software System
Data extraction process involves transferring extracted data from documents into backend systems where it can be stored, analyzed, and utilized for decision-making purposes.
To extract data into cloud storage, you can leverage cloud-based document processing services such as Amazon S3, Google Cloud Storage, or Microsoft Azure Blob Storage. These services offer secure and scalable storage solutions for storing extracted data in the cloud. Extracted data can be transferred to cloud storage using APIs, SDKs, or integration tools provided by the cloud storage providers, enabling seamless integration with document processing workflows.
CRM integration tools or APIs provided by CRM vendors such as Salesforce, HubSpot, or Microsoft Dynamics can help with integrating the extracted data into a CRM of choice. These tools enable organizations to transfer extracted data directly into CRM databases, where it can be used to update customer records, track interactions, and automate sales and marketing processes.
For extracting data into existing software systems, you can leverage integration tools, APIs, or custom integration solutions tailored to their specific requirements.
AI Document Processing: Case Studies
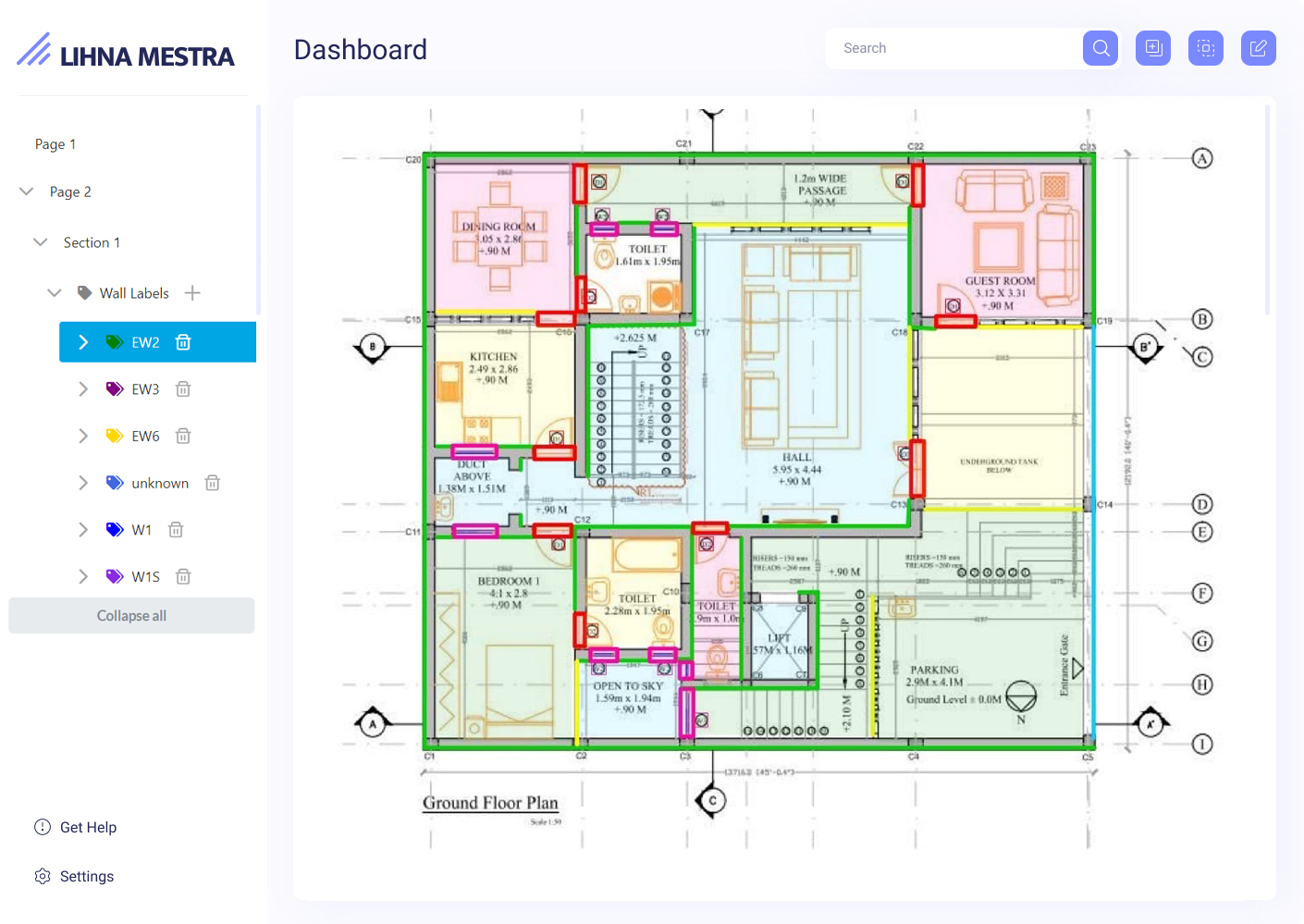
Technical Drawing Recognition System
Technical drawings are among the hardest to process. Despite them being generally uniform in structure, the drawings themselves are always different and complex. This is where intelligent document processing really shines, as it helps extract and digitize data even from the most complex documents.
For our client, we have developed an AI-powered system for processing of technical drawings, including object detection and extraction of complex spreadsheets. The system is capable of detecting rooms, walls, windows and doors in real time, detect technical drawing type and scale, and automatically generates a table of contents, making it easy to navigate large multi-page documents.
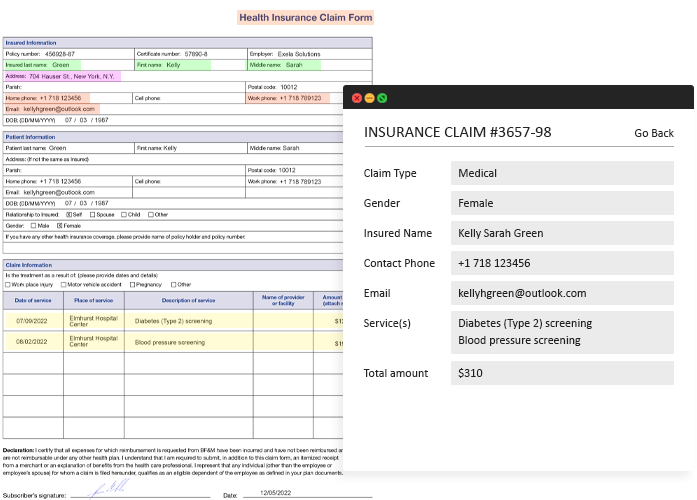
SaaS Data Extraction App For Insurance Claims
The process of manually extracting relevant information from insurance documents is time-consuming and highly error-prone, therefore our client decided to implement an automatic document processing system to help them reduce the workload and improve data extraction quality.
We have created an AI-powered data extraction app for insurance claims that detects document structure and extracts relevant data in a matter of minutes. Our app extracts data from the claims and prepares it for further processing.
Why choose Businessware Technologies as your software development company?
- Businessware Technologies is a reliable AI development vendor: it has been recognised as one of the top software development companies by Clutch and Manifest, it is a Top Rated Plus agency Upwork, and has received local awards for its excellent work,
- A team of over 70 highly skilled software engineers with extensive experience in developing complex software for both startups and Fortune 500 companies,
- Deep expertise in modern AI technologies and approaches to system development, like data science, machine learning, OpenCV, Python, Tesseract, and many more,
- Businessware Technologies is a Microsoft Gold Certified partner,
- Businessware Technologies is compliant with GDPR, ISO 9001, ISO 27001 standards,
- Businessware Technologies works with Fortune 500 companies and has had decades-long relationships with most of its clients,
- Businessware Technologies has proven to be a reliable AI outsourcing partner by having an excellent track record in AI and ML development backed by an extensive portfolio of successful projects.
If you have a computer vision project in mind and need help with implementation, contact our manager and they will be happy to help you.