Processing documents fast and with high accuracy is key to completing a digital transformation. Nowadays, the success of any business’ operations relies on the ability to quickly and easily locate, access and edit document data. Document processing is a use case that is familiar to companies of any size. It has a great impact on a company's productivity regardless of its industry or focus.
Experience AI for Engineering Drawings
Document Detection History: From OCR To AI
Document processing has gone through multiple stages in its development. Traditionally, all document processing was done manually, which had many downfalls. Many companies still deal with challenges like time lost to manual data extraction, incorrect labelling, etc.
To combat these issues, businesses often turn to digitalisation. Many companies are not only processing documents digitally, but are making efforts to migrate to born-digital documents all together.
OCR For Document Digitization
While switching to ‘digital first’ is getting more and more traction each year, most companies still have to convert physical documents into a digital format. This process often includes AI character and font recognition, special symbols recognition, document type recognition, etc. These tasks are solved using OCR, or optical character recognition, which helps to transform a physical document into an editable PDF file, detect, recognise and count special symbols or objects present in a document (which is important for documents that include floor plans, blueprints, etc), detect and recognise images.
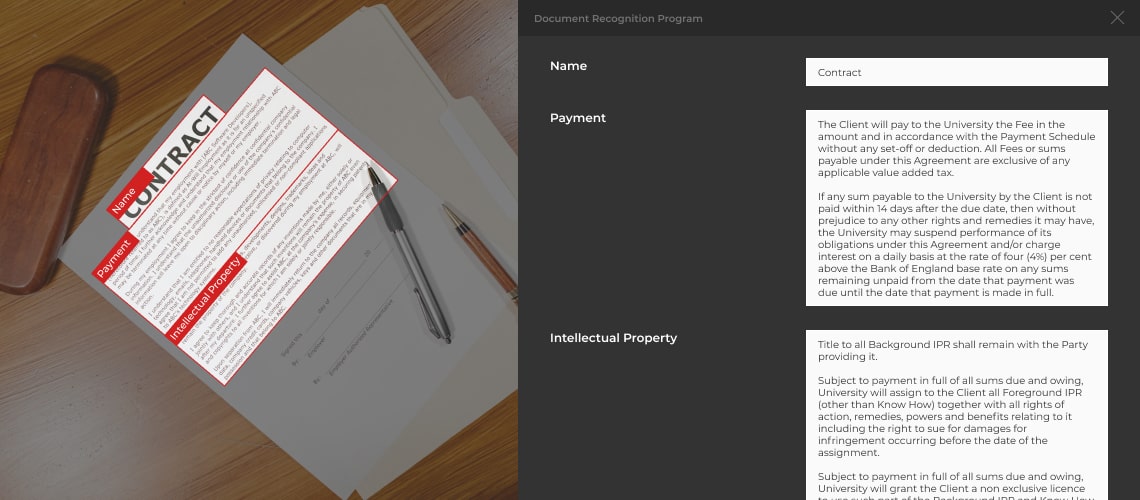
Traditional OCR has significant limitations. The quality of OCR document recognition highly depends on the underlying document processed. Data extraction and classification is only as effective as the quality of the scanned image. OCR often has trouble differentiating between ‘3’ and ‘8’, or ‘O’ and ‘D’. These are the very challenges OCR is supposed to help solve, but instead they become new headaches when the quality of a scanned document is subpar.
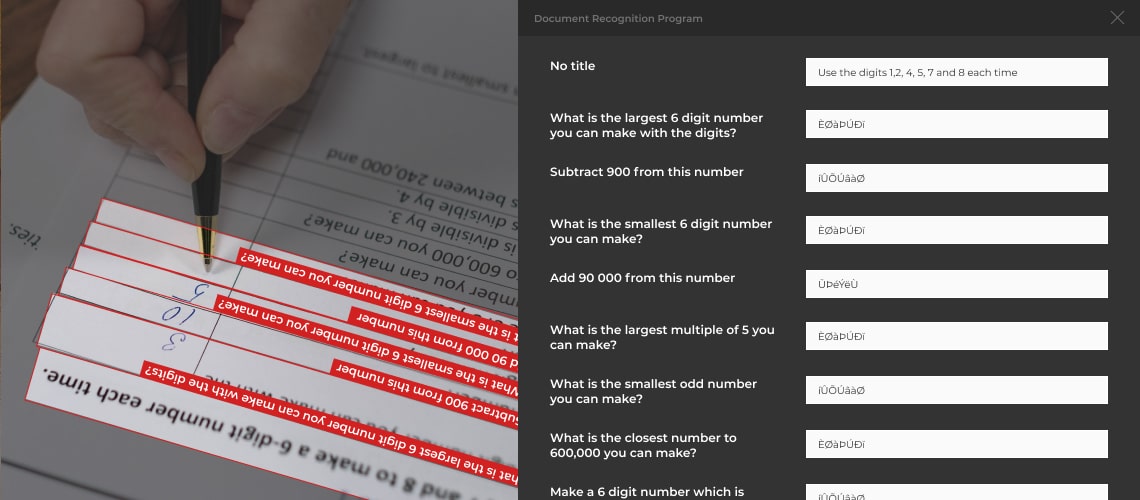
AI-powered Document Recognition
In cases when PDF recognition has to be done with lower quality scans, AI-powered document recognition comes into play. AI capabilities have advanced to the point where it can be used for PDF recognition when traditional OCR fails. Companies that provide custom computer vision services are creating and training machine learning models to apply toward OCR.
Model-based OCR engines, also known as intelligent OCR, provide far better results in document recognition applications, reducing errors and increasing processing speed. AI-powered document recognition helps companies digitize documents that before were challenging for legacy OCR systems, like blueprints, floor plans, handwritten documents, etc.
Turn Construction Drawings into Actionable Data
Floor Plan Recognition
Floor plans and blueprints are more often than not processed manually due to their complex structure and lack of standardisation. One of the primary focuses of floor plan processing is locating various objects, like doors, windows, electrical outlets, etc., as well as digitalisation of text and spreadsheets for editing.
Due to how complex floor plans are, using a standard OCR-based approach for recognition is not effective. Tools that have proven themselves to be reliable for text recognition, like ABBYY and Microsoft, which we have used numerous times for passport recognition, spreadsheet recognition, barcode recognition, and many more, do not provide reliable results in case of blueprint recognition.
Floor plan recognition, when compared to plain text recognition, is more complex. It involves special symbols and abbreviations which present a challenge for ready-made solutions. In order to achieve high quality results, custom computer vision system development is vital.
Machine Learning And AI For Recognising Floor Plans
As floor plans are complex documents that include a variety of sections and elements, the task of digitizing is typically divided into multiple parts according to the task at hand. One may want to digitize spreadsheets that come along with the floor plan to edit them, count how many times a particular symbol is present on the page, detect text, and many more.
Floor Plan Detection: Text
Information about floor plan type, building type, dimensions, etc. is, simply put, a text. Text detection and recognition is a rather simple task when it comes to modern computer vision, however detecting text on a floor plan is more complex. Text specific to floor plans usually contains special symbols, can come in any size, font and color, and can be placed at any angle, rotated to the size or even upside down.
While regular text detection tools, like OCRSpace and IText, can be used with a rather high degree of accuracy for simple text, they are very ineffective when detecting text placed at a weird angle, like object dimensions. To achieve good detection results in these cases, there is a need for custom computer vision development.
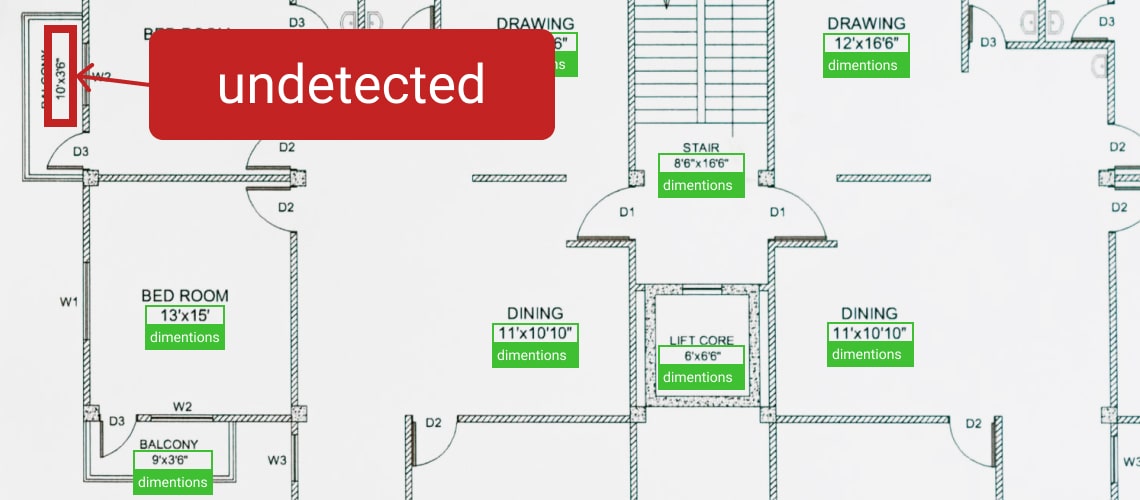
As most OCR tools can be fine tuned, a balancer module can compare different tool settings and choose the ones that produce the most accurate results, as well as compare the results of different tools and choose the best among them. Moreover, fine tuning OCR tools can greatly decrease document processing time - we have managed to achieve up to 200 times acceleration in document processing speed. Using OCR engines like Tesseract can further increase text recognition quality, providing up to 99,9% accuracy.
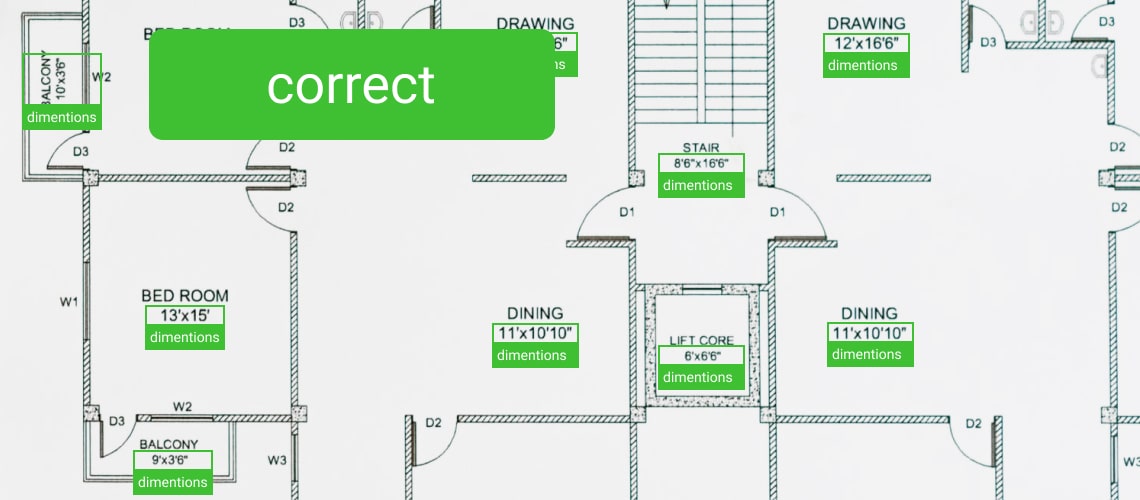
Floor Plan Detection: Labels And Special Symbols
Labels and special symbols which mark specific objects, like doors, windows, electrical outlets, etc. on a floor plan often need to be counted to prepare a bill of quantities or other documentation. This is usually done manually and takes a lot of time, which increases the probability of a mistake.
Labels usually look like geometrical figures which are difficult to distinguish from its surroundings on a floor plan. The variability of labels used to represent the same object also adds to the processing difficulty.
Ready-made computer vision solutions, like OpenCV libraries for symbol detection, work best with color photographs that depict real world objects, like photos of people or animals. Floor plans, on the other hand, are black and white and mostly consist of geometric figures. Regular OpenCV methods work with varied success and often need to be finetuned and built upon to achieve a high enough recognition accuracy sufficient for business needs.
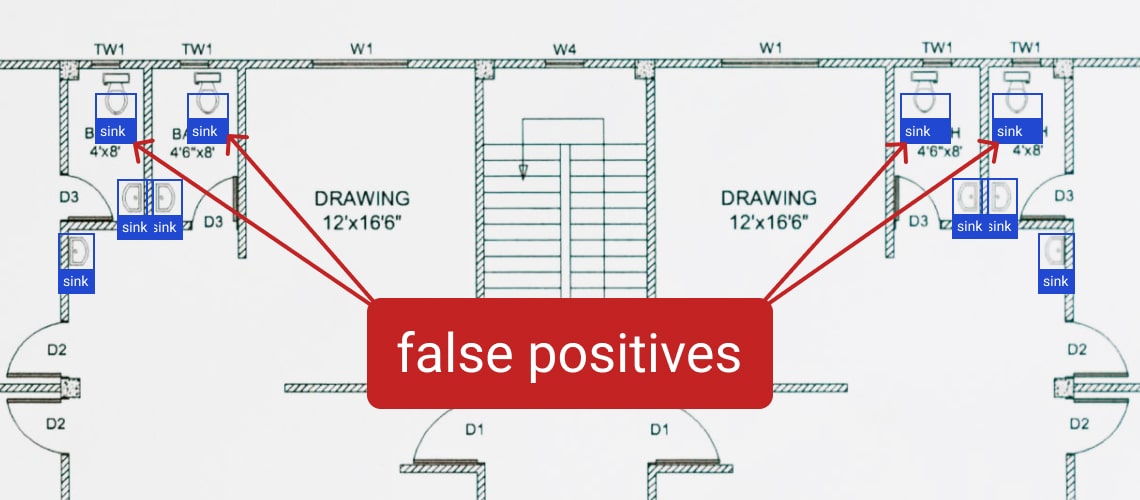
One of the main problems with detecting special symbols on a floor plan is false positive results. Floor plan structure consists of simple geometric shapes, but so do special symbols and labels, making the latter difficult to distinguish from its surroundings. One of the ways this issue can be mitigated is through the use of deep learning. It can be implemented to detect inaccurate detection results and remove them.
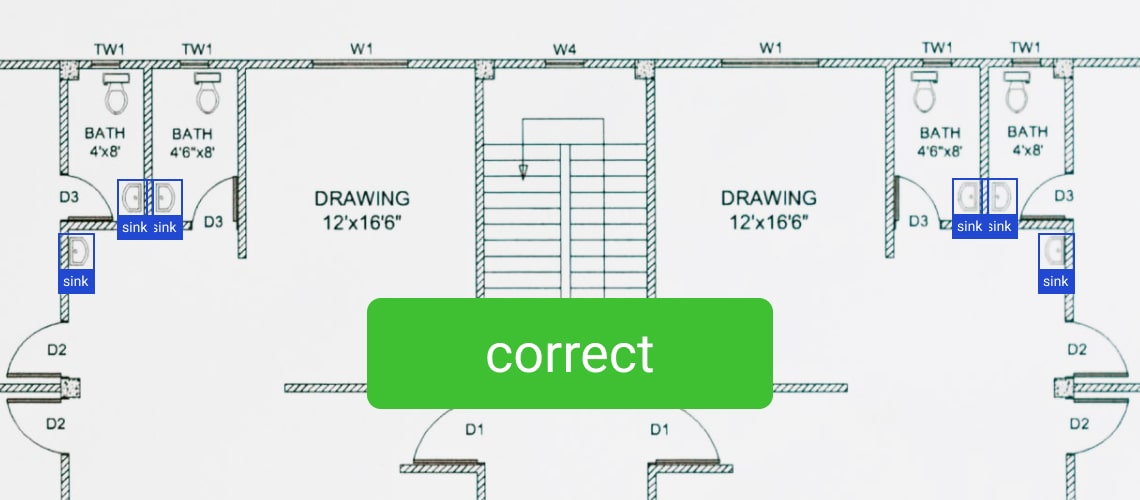
Floor Plan Detection: Images
Some floor plans may include images, both colored and black and white, depicting the exterior of the building or its surroundings. Image recognition is one of the more popular and, as a consequence, more mature area of computer vision. Recognition of images highly depends on the object that needs to be located and categorized, so it makes sense to talk to machine learning developers first hand to see how your project can be brought into reality. Better yet is to get your AI idea validated first - not every idea can be implemented within a reasonable amount of time and within budget constraints.
Build Custom AI for Construction Document Workflows
Conclusion
Floor plan detection, like any other compute vision project, highly depends on the business need behind it. It can be as easy as detecting a small block of text or as complex as creating a fully automated bill of quantities by detecting and counting all objects present on a floor regardless of labels used. Any good project starts with idea exploration and validation to let you know if the idea you have in mind is even possible to implement.
Other document types, like forms filled in by hand, contacts, PDF spreadsheets, and many more, may require different approaches to solving particular detection problems, but the general approach to digitizing any document will remain the same. It is always worth talking to a development team first to see how simple or how complex your project is and how much time and money it would require.