Matching items from supplier RFQs to internal catalogs sounds simple but is slow, inconsistent, and error-prone. Messy descriptions, missing part numbers, and vendor-specific language make accurate matching a constant bottleneck.
The cost adds up: delayed quotes, rework, and preventable mistakes.
LLMs offer a way out, interpreting messy language and recommending likely catalog items to automate much of this work.
But among today’s top LLMs — which one actually performs best for this specific task?
To answer that, we benchmarked 5 leading models on their ability to recommend catalog items based on real RFQ inputs.

The results aren’t theoretical: they reflect actual behavior under realistic procurement conditions.
Read on to learn:
- Which model actually nails catalog matching, and which ones only look good on paper,
- Why a tiny, cheap model beats giants on recall, and what that means for real procurement workflows,
- The hidden bottleneck sabotaging every model’s accuracy (hint: it’s not the LLM),
This benchmark aims to cut through the hype and provide an actionable comparison for those evaluating where to place their bets on AI-driven procurement automation.
Benchmarking 5 Leading Models Against Real Procurement Tasks
To understand how today’s large language models perform in procurement workflows, we ran a controlled benchmark: could they recommend the right catalog items based on real-world RFQs?
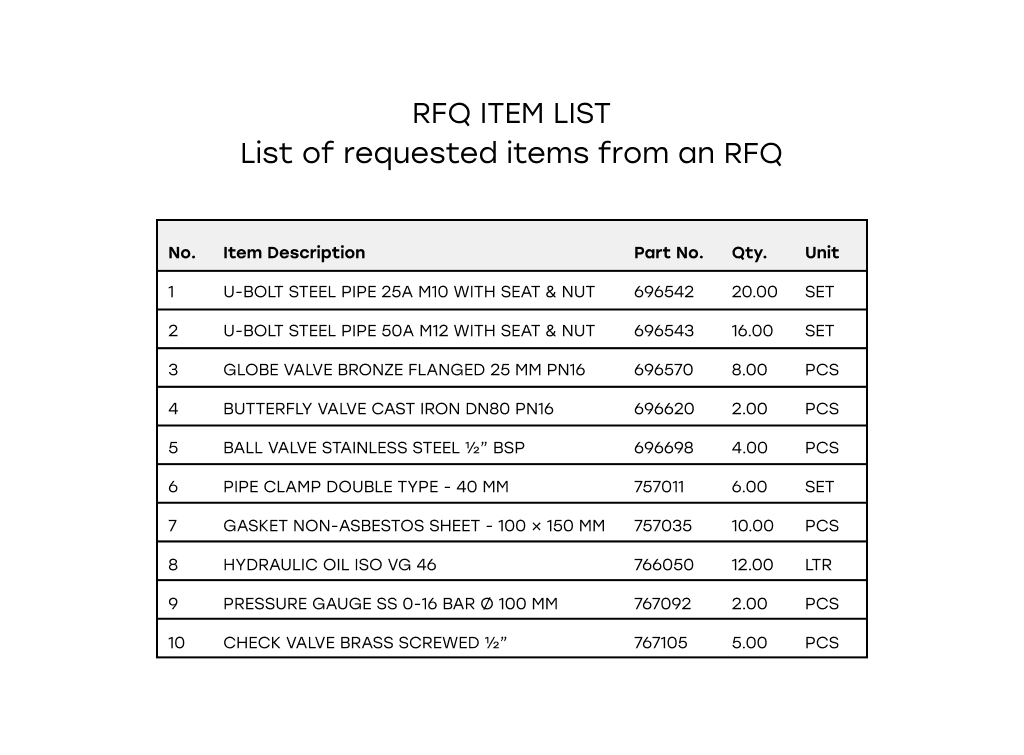
What We Tested
We evaluated five state-of-the-art LLMs across five different vendors:
- GPT-5
- GPT-5 Nano
- Gemini 2.5 Pro
- Claude Sonnet 4
- Grok 4
These models represent some of the most advanced systems available, and some of the most cost-effective for this task.
The Task
We took six real RFQ documents, each containing multiple requested items, a total of 85 items across all samples. For every requested item, the task was:
From a pre-filtered list of catalog items, can the model recommend the right match in its top-5 suggestions?

Each model was given up to 500 candidate items for each RFQ, filtered by a separate retrieval process. The goal wasn’t to reinvent catalog search, but to measure how well models help narrow the decision to the correct item.
How We Scored It
We used three metrics:
- Hit Rate@5: How often the correct item appeared anywhere in the model’s top-5 list,
- MRR (Mean Reciprocal Rank): How close to the top the correct item landed, with a #1 being ideal,
- nDCG@5: A position-weighted ranking score that rewards models for placing the right item near the top.
These metrics together reflect how often and how confidently each model surfaces the right item, both essential for automation.
The result is a practical comparison of recall, ranking quality, and cost that makes it easier to decide which model to deploy depending on whether your priority is minimizing manual review or maximizing top-ranked accuracy.
Benchmark: Best LLM For Invoice Processing in 2025
Benchmark Results: How Each Model Performed
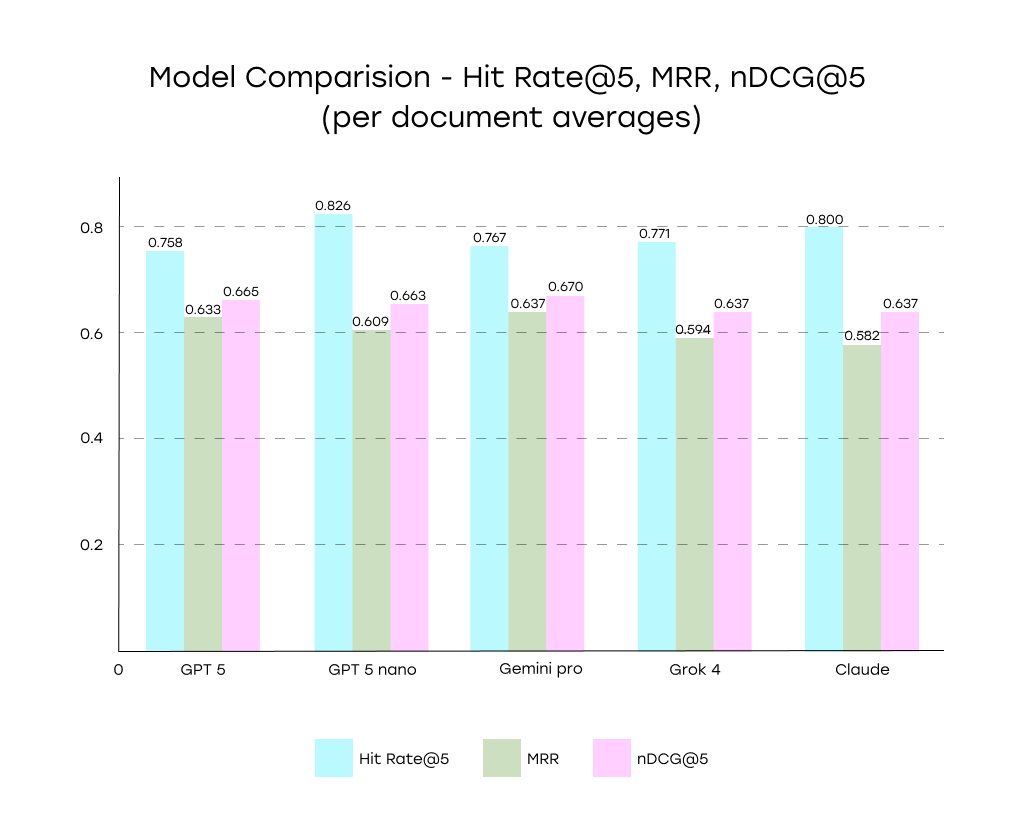
When it comes to using AI for item matching, not all models behave the same. Some are better at making sure the correct item makes the shortlist, others shine when it comes to getting the item exactly right in the top spot.Here’s how the five tested models performed across our three key metrics:
|
Model |
Hit Rate@5 |
MRR |
nDCG@5 |
|---|---|---|---|
|
Gpt 5 |
0.759 |
0.633 |
0.665 |
|
Gpt 5 nano |
0.826 |
0.609 |
0.663 |
|
Gemini 2.5 pro |
0.767 |
0.637 |
0.670 |
|
Grok 4 |
0.771 |
0.594 |
0.637 |
|
Claude sonnet 4 |
0.800 |
0.581 |
0.637 |
Key Insights from the Results
- Best Hit Rate: GPT-5 Nano had the highest Hit Rate@5, meaning it most often included the correct answer somewhere in the top-5. This is ideal if your process is human-in-the-loop and you simply need the right match to be in a shortlist.
- Best Ranking Quality: Gemini 2.5 Pro scored best in both MRR and nDCG@5, placing the correct item closer to the top when it found it. If your workflow relies on trusting the model’s top pick, this is a strong choice.
- Balanced Performer: GPT-5 delivered solid ranking efficiency while achieving a strong hit rate, representing an effective balance of the two behaviors.
- Cost Efficiency Standouts: GPT-5 Nano and Grok 4 offered excellent performance at a fraction of the cost of larger models, making them compelling options for scale.
The Trade-off That Matters
There’s a clear strategic decision here:
- If you want to minimize search effort, look for high Hit Rate — more chances the right item is in the list (e.g., GPT-5 Nano, Claude Sonnet 4),
- If you want fewer correction steps, prioritize high MRR/nDCG — meaning the top-ranked item is more likely to be right (e.g., Gemini 2.5 Pro, GPT-5).
Choosing the right model isn’t just about accuracy; it’s about making the trade-offs that fit your team’s workflow and cost structure.
The specifics of processing RFQs with LLMs
Choosing the right model for procurement automation depends not only on accuracy, but on how that accuracy aligns with workflow goals, cost constraints, and error tolerance. Here’s what the benchmark reveals:
1. Different Models Excel for Different Use Cases
- Maximizing Recall
Models like GPT-5 Nano and Claude Sonnet 4 are highly effective at surfacing the correct item somewhere within the top-5 recommendations. This is especially useful in processes where human reviewers are expected to scan a shortlist and confirm selections.
- Optimizing Ranking Precision
Gemini 2.5 Pro and GPT-5 consistently place the correct item closer to the top. When workflows rely on trusting the model’s first recommendation, these models minimize the need for review or override.
This highlights a crucial trade-off: Should the model prioritize catching more correct items, or placing the correct one at the very top?
2. Cost Efficiency Varies Widely
Performance comes with a price. Here’s the average cost per RFQ:
|
Model |
Average cost per RFQ |
|---|---|
|
$1.2907 |
|
|
$0.0849 |
|
|
$1.0325 |
|
|
$0.0461 |
|
|
$1.6369 |
- GPT-5 Nano offers top-tier recall at a fraction of the cost of larger models.
- Grok 4 is the cheapest option with moderate performance, suitable for non-critical matching tasks or high-volume scenarios.
- Gemini Pro performs strongly in ranking quality with a reasonable price point.
- Claude Sonnet 4 delivers high recall with the highest cost, it should be paired with use cases that justify the expense.
3. Candidate Retrieval is a Critical Bottleneck
Across all models, roughly 21% of ground-truth items were never present in the candidate lists provided. This is a limitation of the pre-filtering step, not the models themselves.
A better retrieval pipeline leads to immediate performance gains even without switching models.
In short: AI models are only as smart as the data you feed them. Improving retrieval logic often yields outsized benefits compared to changing the LLM itself.Workflow Impact: LLMs for Procurement Automation
The benchmark highlights meaningful differences in model behavior, but what does that translate to in a real-world procurement workflow?
1. Reducing Manual Search Time
Models with higher Hit Rate@5, particularly GPT-5 Nano and Claude Sonnet 4, ensure that the correct item appears in the shortlist more often. In practical terms, this means:
- Less time spent hunting for catalog items manually,
- Faster quote generation for RFQs,
- Consistent matching even when item descriptions vary significantly.
If speeding up internal review cycles is a priority, ensuring the correct item is in the top-5 recommendations reduces cognitive load and decision fatigue.
2. Lowering Correction Effort
Models that score higher in ranking accuracy (MRR and nDCG), like Gemini 2.5 Pro and GPT-5, reduce the number of corrections needed when selecting the top result. In workflows where the top-ranked suggestion is directly passed on to quoting or ERP systems, this translates to:
- Fewer manual overrides,
- Lower risk of incorrect items slipping through,
- Faster end-to-end processing.
This precision-focused behavior is useful when the process requires minimal human intervention per RFQ line item.
3. Cost-Effective Scale
Cost per recommendation doesn’t just matter for experimentation, it affects production viability. When matching thousands of items daily, the model’s cost profile directly impacts automation ROI.
For example:
Running GPT-5 Nano for 10,000 RFQs/day costs ~$849/day; Claude Sonnet 4 would cost ~$16,369/day for similar recall — a 19x difference.
Matching strategy needs to balance speed, precision, and cost to maximize efficiency without prohibitive inferencing spend.
Bnehcmark: How well AI handles invoices
Recommendations: The Right Model for RFQ Automation
There’s no universal “best” model in this benchmark. The ideal choice depends on where your workflow values precision, cost efficiency, and automation depth.
Model Trade-offs at a Glance
|
Scenario |
Recommended Model(s) |
Why |
|---|---|---|
|
Reducing search effort for humans |
GPT-5 Nano, Claude Sonnet 4 |
Highest Hit Rate@5 — correct item appears often |
|
Minimizing review or correction steps |
Gemini 2.5 Pro, GPT-5 |
Best ranking accuracy (MRR, nDCG) |
|
Prioritizing cost-effective scale |
GPT-5 Nano, Grok 4 |
Strong performance-to-cost ratio |
|
Trusting the model’s top recommendation |
Gemini 2.5 Pro |
Most often ranks the correct item #1 |
|
Balancing cost and ranking precision |
GPT-5 |
Reliable ranking while staying cost-moderate |

Recommendations by Use Case
- Human-in-the-loop workflows (where operators verify suggested matches):
- Automated item matching (pass-through recommendations):
- Cost-sensitive environments:
Matching catalog items to RFQ requests is a major efficiency bottleneck in procurement, but one that can be significantly improved with the right large language model.
This benchmark shows that:
- Some models excel at always “getting the right answers into the room”,
- Others excel at confidently picking the best answer first,
- Retrieval quality matters as much as model choice.
By understanding model behavior and aligning it with workflow needs, teams can meaningfully reduce quoting time, improve accuracy, and scale procurement operations with less overhead, all while controlling costs.
In many cases, the biggest gains won’t come from upgrading to the "most powerful" model, they’ll come from pairing the right model with a smarter retrieval approach.