AI Agent For Processing Electronic Medical Records
June 2024
A system that recognizes printed and handwritten text in medical questionnaires, extracts and structures responses, correctly processes complex fields, and highlights potentially inaccurate data for review.
The client needed to automate the processing of paper patient questionnaires that are filled out manually before a doctor’s appointment, as well as forms completed by doctors during consultations. These questionnaires contain information about symptoms and the patient’s condition and are used by doctors for initial diagnosis, treatment decisions, and tracking patient progress over time.
Before the solution was implemented, all data was processed manually: after appointments, the questionnaires were scanned and stored as PDF files without any ability to quickly search responses or filter the data.
The goal of the project was to convert handwritten and printed forms into a structured digital format so that doctors could quickly find and analyze patient information.
Initially, it was assumed there would be around 5 different types of forms. In practice, however, the client provided more than 40 different templates. New forms were also added during the course of the project. These forms differed in both structure and completion logic.
This made it impossible to scale the solution by training a separate Azure Document Intelligence model for each form.
The questionnaires included:
In addition, doctors sometimes marked answers in non-standard ways, for example by drawing a vertical line through several answer options, which classical OCR tools do not recognize as separate responses.
Despite generally good recognition quality, the handwriting of patients and doctors, especially in cases where a patient had tremors, led to data interpretation errors.
Basic OCR capabilities could not reliably handle:
It was important for the client not only to extract data, but also to understand the system’s confidence level so that potentially incorrect results could be manually reviewed.
We implemented a hybrid AI document-processing pipeline that combines OCR, CV, and LLMs.
At the start of the project, the team redesigned the forms to make them as structured and standardized as possible. Initially, there were many forms with large handwritten response sections for patients, and answer options were often circled, which made parsing extremely difficult.
To improve the quality of downstream recognition, the documents were changed in the following ways:
The system automatically determines the form type using a classifier based on Azure Document Intelligence and routes the document into the corresponding processing scenario.
We trained the classifier by preparing a training dataset and training the model, so it can now identify which form appears where in a document. This made it possible to process large scanned files containing multiple patients and many forms, split them into separate forms and questionnaires, and then send each form through the pipeline individually.
We use Azure Document Intelligence for:
At the beginning of the project, this approach delivered only about 65–70% accuracy. That level was far too low, so we introduced a hybrid approach: after the initial extraction, the data is passed to the Gemini LLM, which:
Applying this approach increased quality metrics to 95% for simple questionnaires and 90% for complex multi-page questionnaires.

For cases involving “vertical lines,” we implemented a CV model (YOLO) that:

The system generates the final document in Word format, where:
Once document parsing reached a level of quality that satisfied both the client and the development team, we designed the system UI so that the client could see the status of each questionnaire, the reason for any processing failure by Azure or Gemini if such a scenario occurred, and download the recognition result with one click.
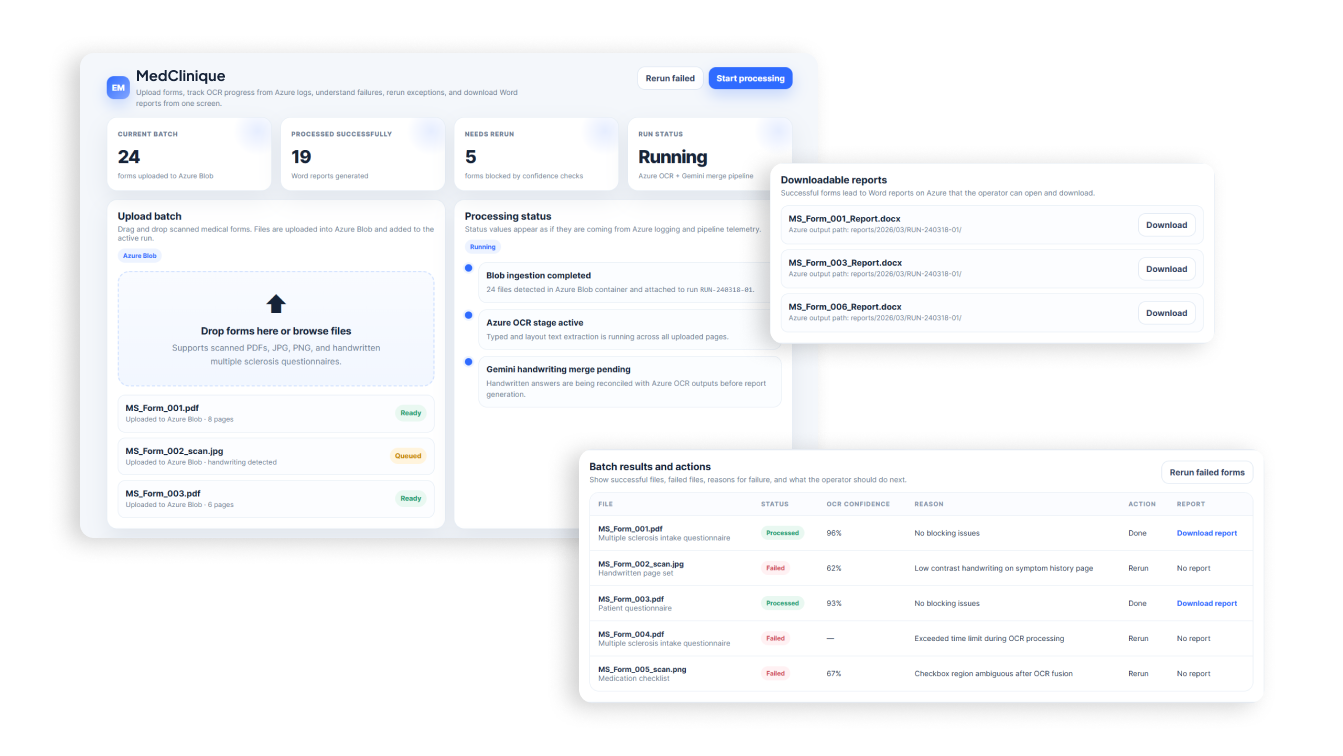
For rapid UI design, we used ChatGPT.
During the project, we not only solved the original task of digitizing manually completed medical questionnaires, but also significantly improved recognition quality compared to the initial approach, from 65% to 95%.
This made it possible to virtually eliminate manual data entry and move questionnaire processing into a digital format. Doctors gained the ability to quickly navigate patient information, search symptom data, and use it for decision-making without having to review scanned documents and decipher different people’s handwriting.
An important part of the solution was the confidence scoring system: potentially inaccurate data is automatically highlighted in red in the final document. This approach helped maintain a balance between automation and quality control, which is especially critical in the medical context.
Despite the achieved results, the project continues to evolve. During real-world use, new business requirements emerged. As a result, the project is gradually evolving from a set of backend services into a full-fledged user tool focused not only on recognition quality, but also on usability and predictability for end users.
Do you want to know the total cost of development and realization of the project? Tell us about your requirements, our specialists will contact you as soon as possible.