Introduction
This benchmark evaluates how well leading AI models extract dimensional and tolerance data from real-world mechanical engineering drawings. Read on to discover:
- Which model topped the benchmark with nearly 80% accuracy — and handled dense annotations other models missed,
- Why one major vision-language model missed up to 90% of dimension data — and which AI services handled complex tolerancing and multi-view layouts reliably,
- How well each model performed on tasks like reference detection, feature counting, and section assignment — and which ones confused or merged critical measurements
We regularly benchmark AI models to find the best ones for digital document processing for different applications. Take a look at our previous report where we’ve tested 7 AI models on schedules (table data) from engineering tables and a comprehensive report on all of our tests.
IDP Models Benchmark
We are constantly testing large language models for business automation tasks. Check out the latest results.
Choosing the Right AI for Engineering Drawings
Engineering drawings are the backbone of manufacturing, used to communicate exact specifications for parts and assemblies across industries like aerospace, automotive, and industrial design.
Among the most critical elements in these technical documents are dimensions — numerical measurements that define the size, location, and tolerances of features on a part. These values are essential for everything from machining and inspection to CAD modeling and quality assurance. Yet, extracting dimensions accurately from engineering drawings remains a significant challenge, especially at scale.
Manual extraction is labor-intensive, error-prone, and difficult to integrate into digital workflows. Automating this task with AI could streamline production pipelines, reduce human oversight, and enable powerful applications such as automated design validation and real-time manufacturing feedback.
However, engineering drawings are visually complex, with dense annotations, variable layouts, and domain-specific symbols. This makes dimension extraction a high-stakes, high-difficulty benchmark for vision-capable AI models.
Experience AI for Engineering Drawings
Tested AI Models
This report presents a comparative analysis of how six models extract technical information from engineering drawings. The study focuses on evaluating the dimensional accuracy, tolerance handling, and structural understanding of each model across a consistent dataset of 10 real-world mechanical drawings.
Note: We initially considered previously tested models like GPT-4o, Grok 2 Vision, and Pixtral Large, but early tests showed that only the most advanced vision-enabled LLMs could reliably parse dense technical drawings. We therefore focused on six high-performance models with strong multimodal architectures and a proven ability to handle complex engineering annotations.
The 6 tested AI models are:
- Gemini 2.5 Flash, or ‘Gemini flash’
- Gemini 2.5 Pro, or ‘Gemini pro’
- ChatGPT o4 mini, or ‘GPT o4 mini’
- ChatGPT o3, or ‘GPT o3’
- Claude Opus 4, or ‘Claude’
- Qwen VL Plus, or ‘Qwen’
Each model was prompted to extract dimensional data from drawing images without fine-tuning.
Dataset & Testing Method
The dataset consists of 10 engineering drawings, each containing between 17 and 58 dimensions of various types:
- Linear dimensions (e.g., distances, heights, depths),
- Radial and diametral dimensions,
- Chamfers and angles,
- Geometric tolerances (such as flatness, perpendicularity, and parallelism),
- Surface roughness annotations,
- Reference and basic dimensions,
- One-sided and two-sided tolerances.
To consider a dimension as correctly recognized, we required correct extraction of all the following fields:
- View Name
- Dimension Type
- Nominal Value
- Feature Count
- Upper Tolerance
- Lower Tolerance
- Tolerance Class
- Is Reference
- Geometric Tolerances (where applicable)
All extractions were manually reviewed and compared to ground truth annotations to assess recognition accuracy.
Benchmark Results: Top AI Models Ranked by Dimension Recognition
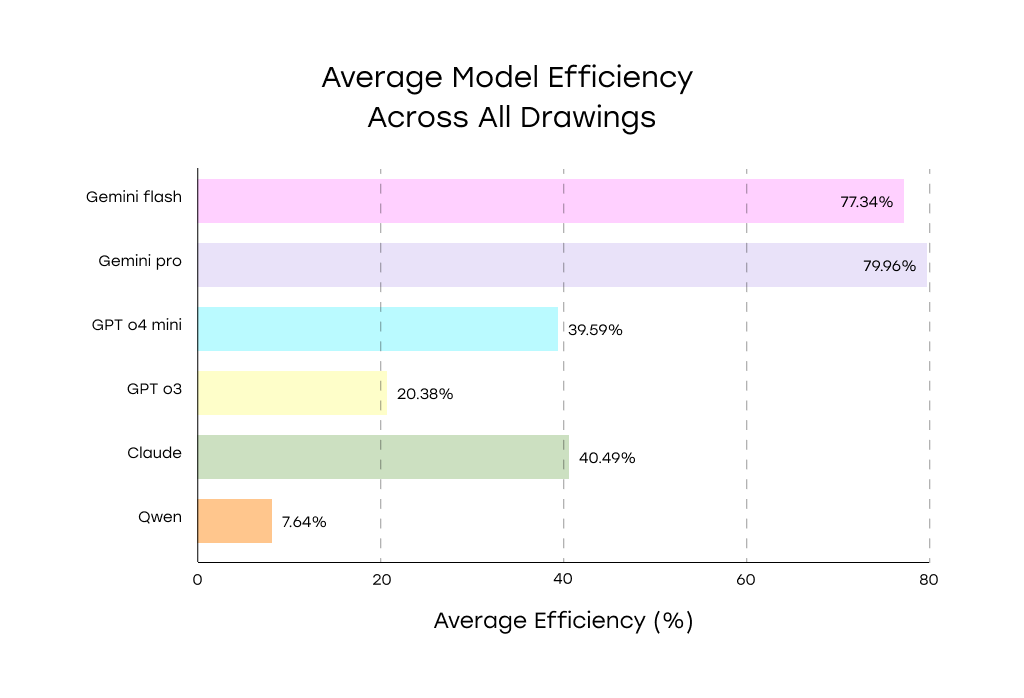
Model Performance Summary
Top Performers
- Gemini Pro (~80%) and Gemini Flash (~77%) led the benchmark, showing strong accuracy on both dimensions and tolerances—even in complex, annotation-dense drawings.
Mid-Tier Models
- Claude Opus (~40%) and GPT-4 Mini (~39.6%) performed well on simpler layouts but struggled with dense annotations and tolerance zones.
- GPT o3 (~20%) offered baseline performance, missing many details without fine-tuning.
Lowest Performer
- Qwen VL Plus (~8%) frequently omitted entire drawing sections, making it unsuitable for automated extraction tasks.
Average Efficiency By Sample
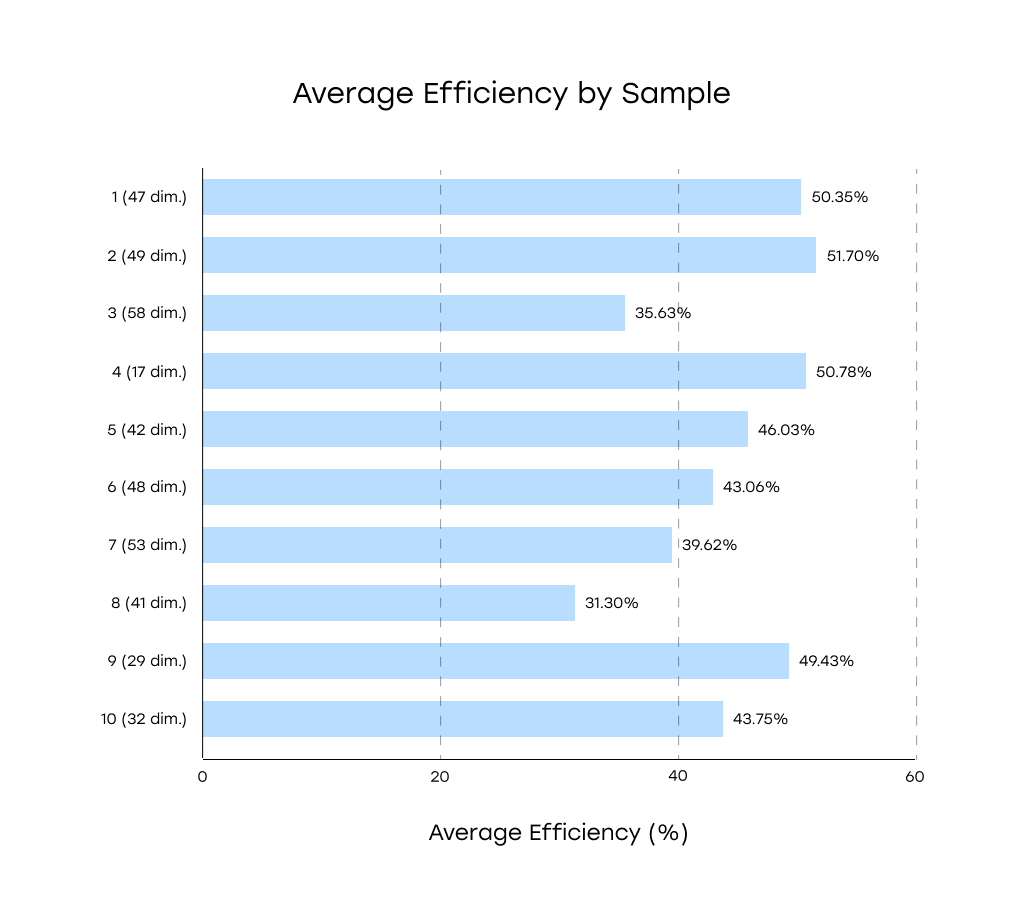
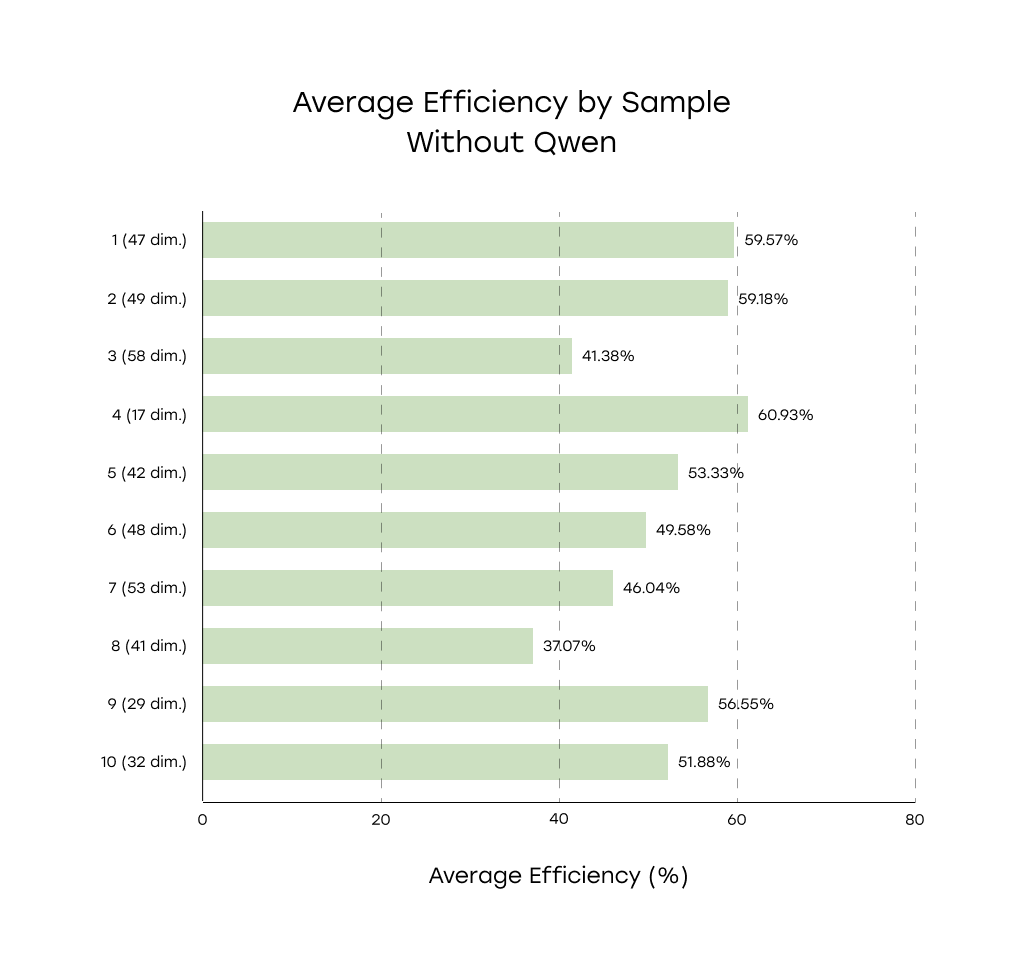
* (N dim.) next to the sample number reflects the actual number of dimensions in the sample
Performance and Cost Comparison
|
Service |
Processing duration per one page |
Average cost per 1000 pages |
|---|---|---|
|
Gemini 2.5 flash |
77.5 s |
$30.5 |
|
Gemini 2.5 pro |
91.4 s |
$130.4 |
|
Gpt o4 mini |
41.75 s |
$24.9 |
|
Gpt o3 |
163 s |
$239.2 |
|
Claude opus 4 |
64.8 s |
$312 |
|
Qwen VL plus |
22 s |
$1.59 |
AI Benchmark Insights: Handling Tolerances, IDs, and Section Assignments in Engineering Drawings
Gemini Pro
Overview: Highest-performing model with strong consistency and robustness across samples.
Average Efficiency: ~80%
Gemini Pro consistently performs well across a range of drawing types and complexity levels. However, in some cases, it merged identical measurements under a single entry and adjusted the “Feature Count” accordingly (e.g., consolidated five identical holes into one feature), rather than listing each measurement separately.
While Gemini Pro generally outperforms its counterpart Gemini Flash, there were individual samples where Flash achieved higher extraction efficiency, suggesting that Flash may be better tuned for certain annotation styles or layout types.
Gemini Flash
Overview: Close second to Gemini Pro with strong performance and occasional lead in specific cases.
Average Efficiency: ~77%
Like Pro, Gemini Flash excels at extracting both geometric dimensions and tolerances. However, the model struggles with mixed one-sided and two-sided tolerances (Drawing 5). While it correctly extracted nominal values, the model struggled to interpret mixed one-sided and two-sided tolerances, often inserting a second tolerance value even when only one was explicitly specified.
Notably, on several samples, Flash outperformed Gemini Pro, despite the latter’s enhanced reasoning capabilities.
GPT o4 Mini
Overview: Mid-tier performer with strong results on clean drawings but issues in complex contexts.
Average Efficiency: ~39.6%
GPT?o4 Mini delivers good precision on cleaner drawings but has issues in complex layouts. Like Gemini Pro, it sometimes merged identical measurements into one and changed the “Feature Count”. It also exhibited occasional mismatches between upper and lower tolerance values, which can affect interpretation accuracy.
GPT o3
Overview: Baseline-level performance; not production-ready without additional support.
Average Efficiency: ~20%
GPT o3 often failed to detect dimension identifiers or misassigned them to incorrect measurements. While these issues were not considered formal failures, they undermine traceability and complicate validation, particularly in quality-critical applications.
GPT o3 also showed occasional deviations in upper and lower tolerance values, further reducing reliability. Without fine-tuning or additional post-processing, its output lacks the consistency needed for production use.
Claude Opus
Overview: Mid-tier model with solid performance in moderately complex layouts.
Average Efficiency: ~40%
Claude Opus performs reasonably well on drawings with moderate complexity. However, it occasionally misassigns dimensions to the wrong sections, indicating weaker capabilities in localizing annotations within multi-view layouts.
Qwen VL Plus
Overview: Significantly underperforms; not viable for this task in current form.
Average Efficiency: ~8%
Qwen frequently omitted entire sections of the drawing and failed to segment layouts into distinct views such as main and detail sections. As a result, many context-specific dimensions were lost, making the model unsuitable for automated dimension extraction. Qwen also misassigned dimensions to incorrect sections, further impacting reliability.
General Insights Across Models
Consistency Across Samples
The average detection efficiency across all drawings remained relatively consistent, ranging from 31% to 51%.
Despite differences in layout density, annotation style, and tolerance detail, most models exhibited comparable levels of extraction accuracy across samples.
Conclusion: Layout density and annotation style were not dominant factors in determining model accuracy.
Geometric Tolerances: A Shared Weakness
Across all tested models, standalone geometric tolerances (e.g., perpendicularity, parallelism, flatness) proved problematic. In many cases, models either misclassified the tolerance type or omitted these features entirely.
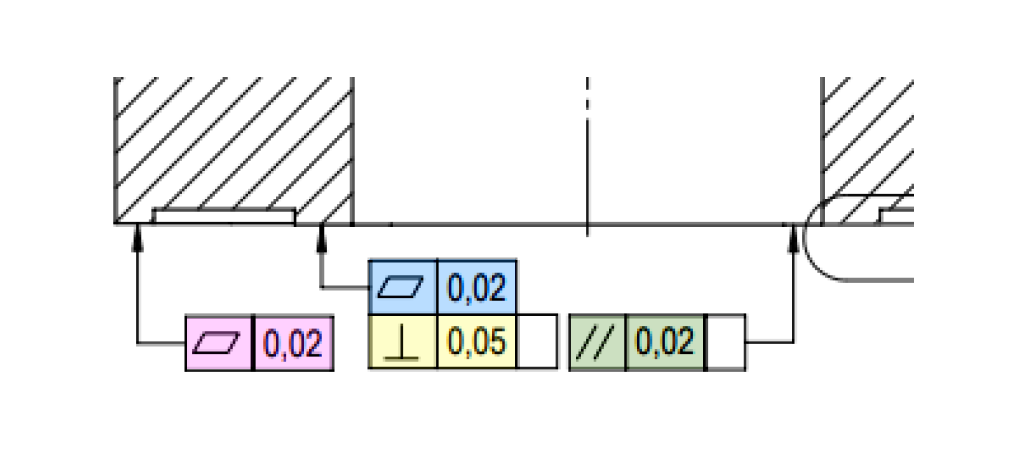
Section Assignment and View Name Detection
Most models demonstrated strong capability in associating each dimension with its correct drawing section or projection and accurately recognizing the section titles when present.
Exceptions: Claude and Qwen occasionally misassigned dimensions, reflecting weaker multi-view spatial understanding.
Turn Construction Drawings into Actionable Data
How to Maximize AI Dimension Extraction Accuracy from Technical Drawings
In our analysis, no single AI model was able to consistently extract all dimensions from complex engineering drawings. Differences in layout, annotation density, and tolerance formats often caused models to miss or misinterpret measurements.
To improve reliability and coverage, we recommend two complementary strategies:
Model Ensemble
Combine outputs from multiple models to capitalize on their unique strengths:
- One model may handle linear dimensions better,
- Another may perform best with geometric tolerances or dense annotations.
Benefits:
- Increased recall across drawing types
- Reduces the need for manual correction
- Captures more callouts by leveraging complementary capabilities
Iterative Inference Passes
Run the same model multiple times, using slight variations in prompts or initialization. This helps uncover dimensions missed in the first pass.
Benefits:
- Boosts overall coverage
- Minimizes false negatives
- Especially useful when constrained to a single model
Final Evaluation: Best AI Models for Engineering Drawing Dimension Extraction
Model Performance & Accuracy

- Gemini Pro and Gemini Flash stand out as the top performers, with extraction accuracies approaching 80%. Both handle complex dimension types and tolerances well, making them strong candidates for integration into automated CAD or QA pipelines.
- Claude Opus and GPT-o4 Mini offer moderate accuracy (~40%), suitable for simpler drawings or use cases where occasional errors are acceptable.
- GPT-o3 delivers baseline-level performance, but often struggles with tolerance handling and identifier mapping.
- Qwen VL Plus is currently not viable for this task, failing to detect a majority of dimensions and context-specific annotations.
Cost and Efficiency Considerations
- Qwen VL Plus was the fastest and cheapest (22 s/page, $1.59/1,000 pages), but its poor accuracy makes it unsuitable for use.
- GPT-o4 Mini offered the best tradeoff between speed and cost (42 s/page, $24.90), viable for low-complexity tasks with post-processing.
- Gemini Flash delivered strong accuracy at reasonable cost (77.5 s/page, $30.50), making it a balanced option for high-volume use.
- Gemini Pro was the most accurate but slow (91.4 s/page) and expensive ($130.40), best reserved for high-precision needs.
- Claude Opus (64.8 s/page, $312) and GPT-o3 (163 s/page, $239.20) were both too costly and underperformed relative to peers—offering poor overall value.
- GPT-o3 was the slowest (163 s/page) and among the most expensive ($239.20), with subpar accuracy, making it inefficient for any practical deployment.
Final Recommendations
- For critical applications requiring high-accuracy dimensional extraction—particularly those involving tolerances, geometric features, and multi-view layouts—Gemini 2.5 Pro remains the most capable and reliable model, albeit with higher cost and processing time.
- Gemini 2.5 Flash provides nearly comparable performance at significantly lower cost and speed, making it the most practical choice for high-volume workflows or scenarios with moderate layout complexity.
- GPT-o4 Mini is acceptable for lower-risk applications or basic extraction needs, where some tolerance for field-level omissions exists. Its speed and affordability make it appealing when accuracy demands are relaxed.
- Claude Opus and GPT-o3 are not recommended due to high cost, limited accuracy, and slower performance. Both models require significant manual correction to be usable.
- Qwen VL Plus, while fast and inexpensive, lacks the structural recognition and precision necessary for engineering drawing analysis and should be avoided in automated workflows.